中文分词器 #
-
分词,一定是建立在创建“倒排索引”之前。ES将字符串划分为2种类型:Keyword和Text
-
ES不会针对Keyword进行分词,它只会针对Text进行分词
-
ES常见的中文分词器:ik_max_word,ik_smart
ik_max_word:细粒度的分词 #
- 举例:
doc {desc: "中华人民共和国国歌"} - 结果:中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、共和、人、国歌
ik_smart:粗粒度的分词 #
举例:doc {desc: "中华人民共和国国歌"}
- 中华人民共和国
- 国歌
ES的中文分词安装 #
方式一:在线安装(不推荐) #
- 进入容器后,执行在线安装命令
#进入容器
docker exec -it es /bin/bash
#执行命令进行安装
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v6.8.2/elasticsearch-analysis-ik-6.8.2.zip
方式二:离线安装 #
进行下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
1、上传zip文件到服务器 #

2、重新启动elk容器,需要将插件目录映射出来 #
docker run -dit --name elk \
-p 5601:5601 \
-p 9200:9200 \
-p 5044:5044 \
-v /root/elk/elk-data:/var/lib/elasticsearch \
-v /root/elk/elasticsearch/plugins:/opt/elasticsearch/plugins \
--privileged=true \
sebp/elk:700
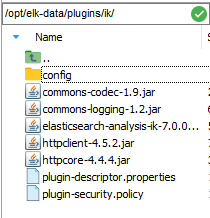
3、将zip文件解压到映射出来的/root/elk/elasticsearch/plugins目录中
#
如果没有安装unzip,需要进行安装
#下载解压工具
yum install unzip
#解压
unzip elasticsearch-analysis-ik-7.0.0.zip
4、重启elk容器 #
docker restart elk
docker logs -f elk
5、Kibana中测试中文分词器 #
GET /_analyze
{
"text": "提醒广大群众,如您是从黑龙江省有疫情发生地区及国内中高风险地区返(来)吉人员,或是与以上无症状感染者有接触的人员,必须主动向当地社区(村屯)报告,同时配合进行管控与核酸检测。为减少疫情传播风险,大家要不聚集、讲卫生、戴口罩、保持安全社交距离,一旦出现发热、咳嗽等急性呼吸道症状,请佩戴医用口罩及时到当地定点医疗机构发热门诊就诊",
"analyzer": "ik_max_word"
}