分布式事务 #
分布式事务概念 #
- 本地事务:单体应用对应的单个数据库的事务
- 事务的目的:保证整个业务流程,要么统一成功,要么统一失败
- 通过单体应用中的事务管理器(TransactionManagement),可以保证事务的完整性
- 分布式事务
- 现在,我们用的是微服务。微服务的特点:一个微服务对应一个数据库
- 分布式程序,或微服务程序是相互独立的模块,都是远程调用,无法继续使用本地事务控制
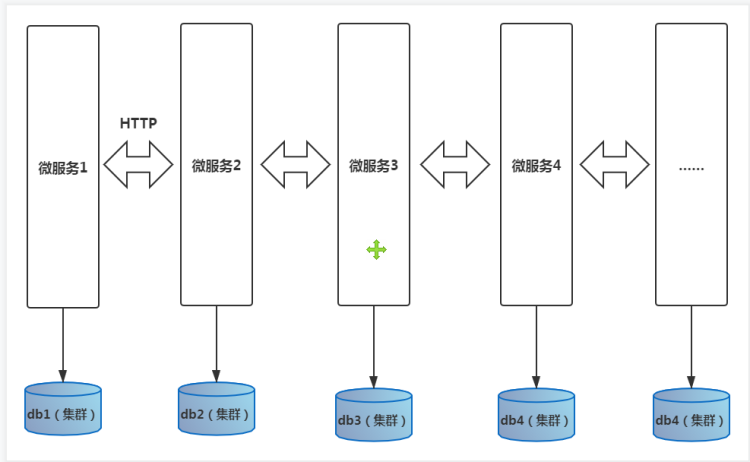
产生的背景 #
-
系统越来越大,数据量越来越多,就不可避免的需要做数据库的分库,分片,分表
-
不同的数据定位在不同的数据库中,不同的数据库又对应着不同的微服务,这就变成了跨库操作,以前的本地事务@Transactional就没用了
-
不同的数据库对应的不同的微服务,每个微服务又有了它自己的业务逻辑,并且微服务之间又是相互独立的,此时:微服务相互调用过程中,就很难做到保证整个业务链条过程中,业务保持完整性
-
不同的数据库,还有可能分配在不同的机房中,甚至有可能在不同的网络中,进一步加深了咱们分布式事务控制难度
分布式事务解决方案 #
全局事务(2PC) #
2 Prepared Commit
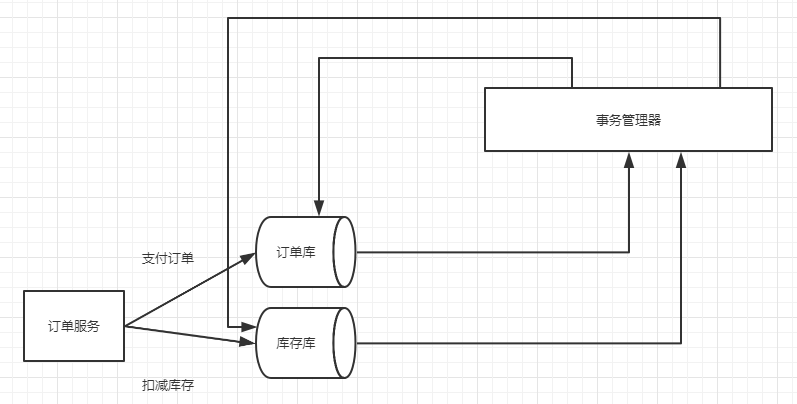
全局事务基于DTP模型实现。DTP是由X/Open组织提出的一种分布式事务模型–X/Open Distributed Transcation Processing Reference Model。它规定,要实现分布式事务的话,就需要三种角色:
- AP:Application 应用系统(参与者)
- TM:Transaction Manager 事务管理器(全局事务管理者)
- RM:Resource Manager 资源管理器(本地事务管理者,即数据库,也可以是其他资源管理器, 比如消息队列,文件系统)
阶段一:表决阶段,所有参与者都预提交(只执行sql,但不提交)事务,并将能都成功的信息反馈发给协调者。
事务协调者(事务管理器)给每个参与者(资源管理器)发送 Prepare 消息,每个参与者要么直接返回失败(如权限验证失败),要么在本地执行事务,写本地的 redo 和 undo 日志,但不提交,到达一种“万事俱备,只欠东风”的状态。
阶段二:执行阶段,协调者根据所有参与者的反馈,通知所有参与者,步调一致地执行提交或者回滚。
如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行提交或者回滚操作,释放所有事务处理过程中使用的锁资源。(注意:必须在最后阶段释放锁资源)
优缺点 #
- 优点
- 提高了数据一致性的概率,实现成本较低
- 缺点
- 单点问题:事务协调者宕机
- 同步阻塞:延迟了提交时间,加长了资源阻塞时间
- 数据不一致:在第二阶段提交时,依然存在commit结果未知的情况,有可能导致数据不一致
- 数据不一致(脑裂问题)
- 在二阶段提交的阶段二中,当协调者向参与者发送 commit 请求之后,发生了局部网络异常或者在发送 commit 请求过程中协调者发生了故障,导致只有一部分参与者接受到了commit 请求。于是整个分布式系统便出现了数据部一致性的现象(脑裂现象)。
TCC两阶段补偿性方案 #
数据库的事务,为逻辑业务处理
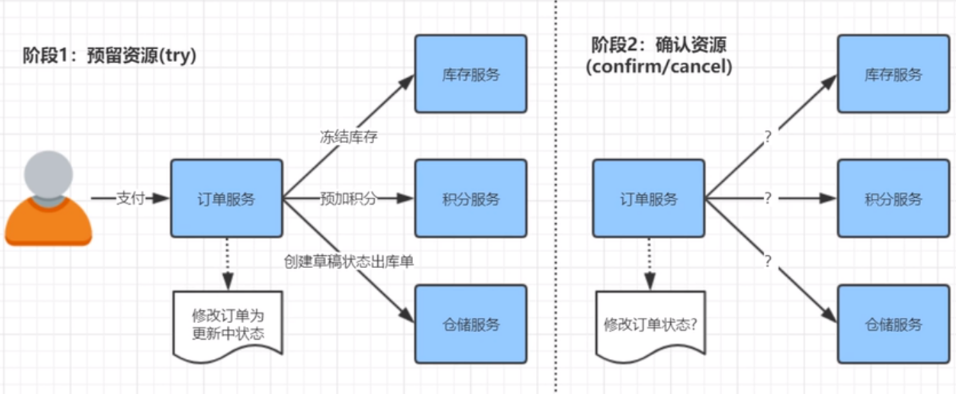
TCC,Try Confirm Cancel,它属于补偿型事务。顾名思义,TCC实现分布式事务一共有三个步骤:
-
Try:尝试待执行的业务
这个过程并未执行业务,只是完成所有业务的一致性检查,并预留好执行所需的全部资源
-
Confirm:确认执行业务
确认执行业务操作,不做任何业务检查,只使用Try阶段预留的业务资源。通常情况下,采用TCC则认为Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。若Confirm阶段真的出错了,需引入重试机制或人工处理。
-
Cancel:取消待执行的业务
取消Try阶段预留的业务资源。通常情况下,采用TCC则认为Cancel阶段也是一定会成功的。若Cancel阶段真的出错了,需引入重试机制或人工处理。
- TCC两阶段提交与XA两阶段提交的区别是:
- XA是资源层面的分布式事务,强一致性,在两阶段提交的过程中,一直会持有资源的锁
- TCC是业务层面的分布式事务,最终一致性,不会一直持有资源的锁
- TCC事务的优缺点
- 优点:执行完每个阶段就commit,不会长时间占有资源。提高了整个系统的并发量。
- 缺点:TCC的Try、Confirm和Cancel操作功能需业务提供,开发成本高。
分布式事务中间件 #
Seata #
官网地址:http://seata.io/zh-cn/
Seata是由阿里中间件团队发起的开源项目 Fescar,后更名为Seata,它是一个是开源的分布式事务框架。致力于在微服务架构下提供高性能和简单易用的分布式事务服务。(AT模式是阿里首推模式,阿里云上有商用版本的GTS[Global Transaction service全局事务服务])。
它通过对本地关系数据库的分支事务的协调来驱动完成全局事务,是工作在应用层的中间件。主要优点是性能较好,且不长时间占用连接资源,它以高效并且对业务0侵入的方式解决微服务场景下面临的分布式事务问题,它目前提供AT模式(即2PC)及TCC模式的分布式事务解决方案。
发展史 #
2014 - 阿里中间件团队发布txc(taobao transaction constructor)在阿里内部提供分布式事务服务; 2016 - txc经过改造和升级,变成了gts(global transaction service)在阿里云作为服务对外开放,也成为当时唯一一款对外的服务; 2019 - 阿里经过txc和gts的技术积累,决定开源(Apache开源协议)。并且,在github上发起了一个项目叫做fescar(fast easy commit and rollback)开始拥有了社区群体; 2019 - fescar被重命名为了seata(simple extensiable autonomous transaction architecture),项目迁移到了新的github地址。
全局事务 #
AT 模式是一种无侵入的分布式事务解决方案。在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
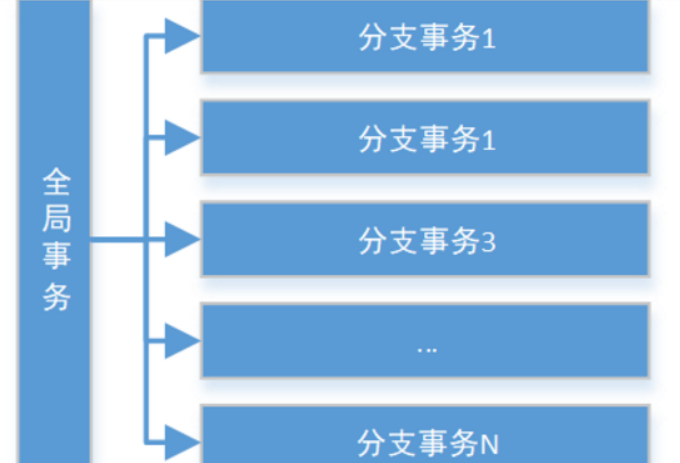
Seata把一个全局事务,看做是由一组分支事务组成的一个大的事务(分支事务可以直接认为就是本地事务)
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata把一个分布式事务理解成一个包含了若干分支事务的全局事务。全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个关系数据库的本地事务,下图是全局事务与分支事务的关系图:
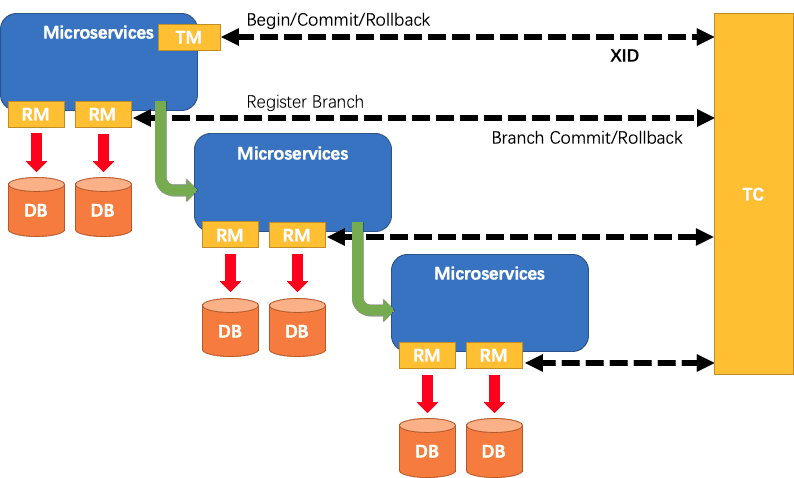
Seata中的三个组件 #
Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚。
Transaction Manager (TM): 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议。
Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
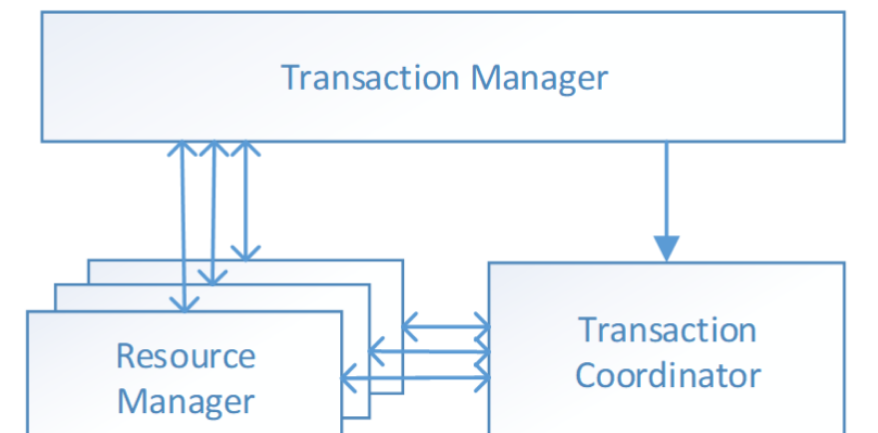
Seata管理分布式事务的典型流程 #
- TM创建全局事务,告知TC,TC生成全局唯一的XId
- 在TM中调用分支事务RM,将xid传给RM。
- RM通过xid注册的TC中,告知TC他是哪一个全局事务的分支事务。
- TM告知TC,可以进行提交或者回滚了。
- 由TC通知TM对应的RM进行提交或回滚。
Seata安装与启动 #
1、下载seata #
下载地址:https://github.com/seata/seata/releases
2、修改conf/registry.conf
#
将原来的模板全部删除,粘贴下面的
registry块用以控制将TC注册在哪里(注册中心),config块用以控制将TC的配置文件交由谁来管理(配置中心)
registry {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
}
config {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
}
3、修改conf/nacos-config.txt
#
定义某个事务组,属于哪个TC集群
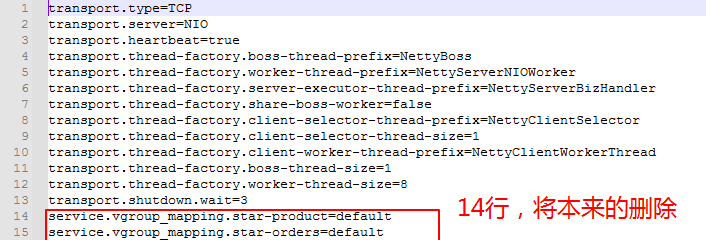
service.vgroup_mapping.micro-product=default
service.vgroup_mapping.micro-orders=default
其中,micro-product和micro-orders是事务分组的名字,其后的取值“default”是TC集群的名字
4、将seata的配置文件存入配置中心 #
确保nacos已经运行
在conf目录下,执行nacos-config.sh脚本,该脚本能把seata TC所需要的配置存入nacos配置中心
进入nacos控制台,查看配置列表,可以看到很多Group为SEATA_GROUP的配置
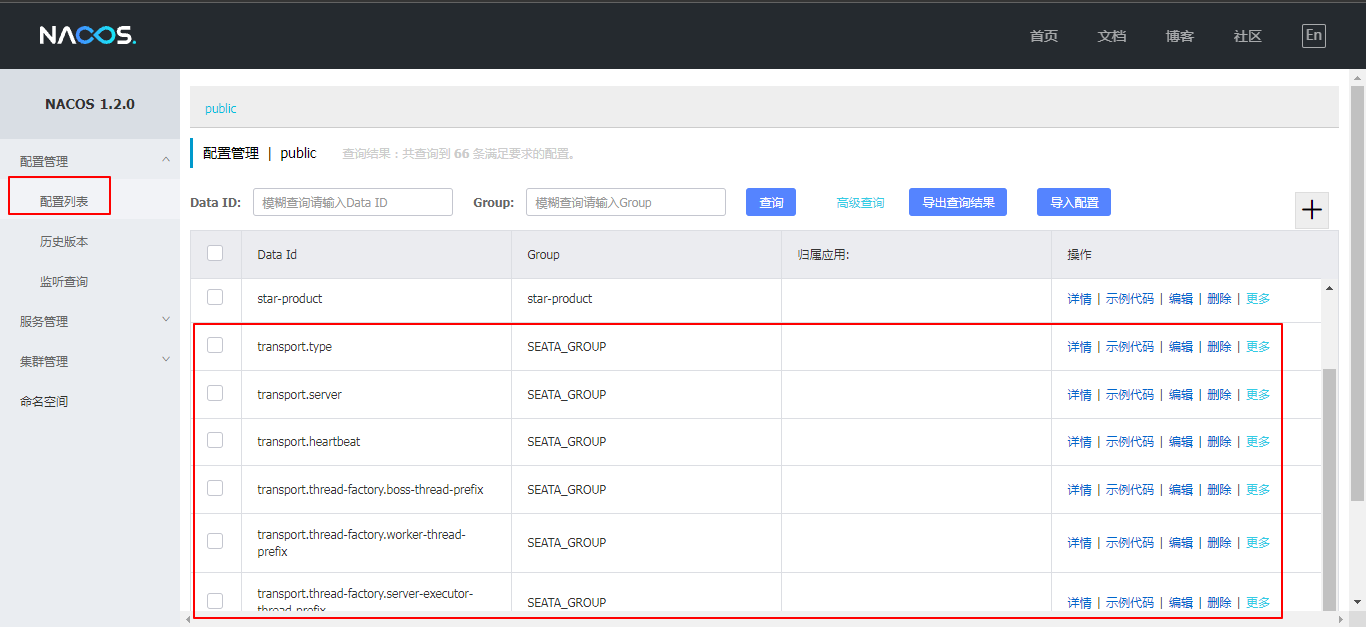
5、启动seata服务(TC) #
bin目录下
默认占用的端口是8091,可以在启动seata-server时,通过-p指定端口
seata-server.bat -p 8091 -m file
启动后,在nacos的服务列表下面可以看到一个名为serverAddr的服务
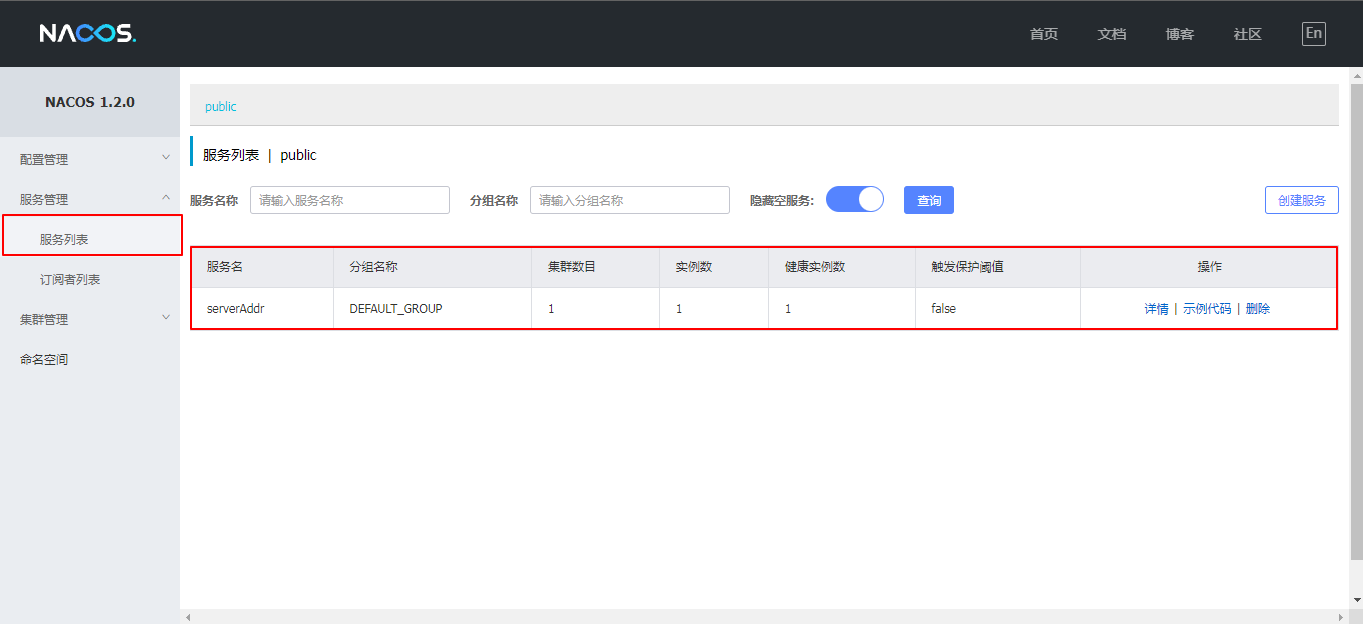
微服务中使用Seata #
1、在需要进行事务管理的微服务中添加依赖 #
如果只加依赖,不进行下面的配置,启动会报错
依赖中封装了(TM、RM)
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>
2、每个微服务添加初始化数据表 #
初始化数据表:在每个微服务的项目数据库中加入一张undo_log表,这是Seata记录事务日志要用到的表
-- the table to store seata xid data
-- 0.7.0+ add context
-- you must to init this sql for you business databese. the seata server not need it.
-- 此脚本必须初始化在你当前的业务数据库中,用于AT 模式XID记录。与server端无关(注:业务数据库)
-- 注意此处0.3.0+ 增加唯一索引 ux_undo_log
drop table `undo_log`;
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`branch_id` bigint(20) NOT NULL,
`xid` varchar(100) NOT NULL,
`context` varchar(128) NOT NULL,
`rollback_info` longblob NOT NULL,
`log_status` int(11) NOT NULL,
`log_created` datetime NOT NULL,
`log_modified` datetime NOT NULL,
`ext` varchar(100) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
3、在需要进行事务管理的微服务添加配置类 #
在star-orders和star-product的config包中,创建以下配置类,在其中配置代理数据源,该代理数据源主要添加了日志记录功能,TC通过该日志才能够进行回滚!也就是说这一步必不可少!!
//普通数据源
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource") //读取yml中的配置
public DriverManagerDataSource dataSource(){
return new DriverManagerDataSource();
}
// 必须在代理数据源上添加@Primary,保证在自动装配时优先注入代理数据源
@Primary
@Bean
public DataSourceProxy dataSource(DriverManagerDataSource driverManagerDataSource) {
return new DataSourceProxy(driverManagerDataSource);
}
}
//druid数据源
@Configuration
public class DataSourceProxyConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource") //读取yml中的配置
public DruidDataSource druidDataSource() {
return new DruidDataSource();
}
// 必须在代理数据源上添加@Primary,保证在自动装配时优先注入代理数据源
@Primary
@Bean
public DataSourceProxy dataSource(DruidDataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
}
4、修改微服务启动类 #
启动类上去掉默认的数据库链接,否则容易造成死循环
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
5、微服务添加seata的配置文件registry.conf #
用于告诉应用中的TM,去哪里找TC
registry {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = ""
}
}
config {
type = "nacos"
nacos {
serverAddr = "localhost"
namespace = ""
}
}
6、修改微服务的配置文件application.yml #
用于告诉应用中的TM,去哪里找TC
要与nacos-config.txt中的service.vgroup_mapping.micro-orders=default一致
spring:
cloud:
alibaba:
seata:
tx-service-group: micro-orders
7、在微服务控制层方法,开启全局事务 #
添加注解@GlobalTransactional
@GetMapping("/addOrderProduct/{uid}")
@GlobalTransactional
public ResultVO addOrderProduct(@PathVariable Integer uid){
}
测试时,记得关闭micro-orders中的ProductService的后备方法
CAP理论 #
C:Consistency – 一致性,在分布式系统完成某写操作后任何读操作,都应该获取到该写操作写入的那个最新的值。相当于要求分布式系统中的各节点时时刻刻保持数据的一致性。
A:Availability – 可用性, 一直可以正常的做读写操作。简单而言就是客户端一直可以正常访问并得到系统的正常响应。用户角度来看就是不会出现系统操作失败或者访问超时等问题。
P:Partition Tolerance – 分区容错性,指的分布式系统中的某个节点或者网络分区出现了故障的时候,整个系统仍然能对外提供满足一致性和可用性的服务。也就是说部分故障不影响整体使用。
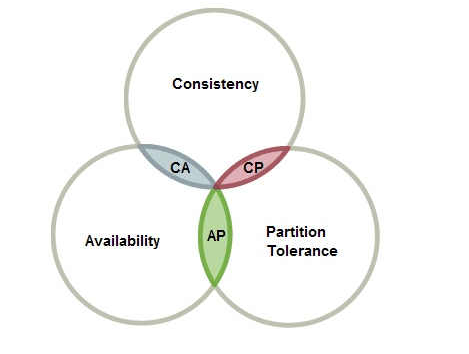
CAP三者不可兼得,该如何取舍 #
(1) CA: 优先保证一致性和可用性,放弃分区容错。 这也意味着放弃系统的扩展性,系统不再是分布式的,有违设计的初衷。
(2) CP: 优先保证一致性和分区容错性,放弃可用性。在数据一致性要求比较高的场合(譬如:zookeeper,Hbase) 是比较常见的做法,一旦发生网络故障或者消息丢失,就会牺牲用户体验,等恢复之后用户才逐渐能访问。
(3) AP: 优先保证可用性和分区容错性,放弃一致性。NoSQL中的Cassandra 就是这种架构。跟CP一样,放弃一致性不是说一致性就不保证了,而是逐渐的变得一致。
分布式锁 #
分布式锁的特点 #
- 互斥性。在任意时刻,只有一个客户端能持有锁
- 不会发生死锁。即使有一个客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。
- 具有容错性。只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。
- 解铃还须系铃人。加锁和解锁必须是同一个客户端,其他客户端无法对已经加锁的数据进行解锁操作
Redission #
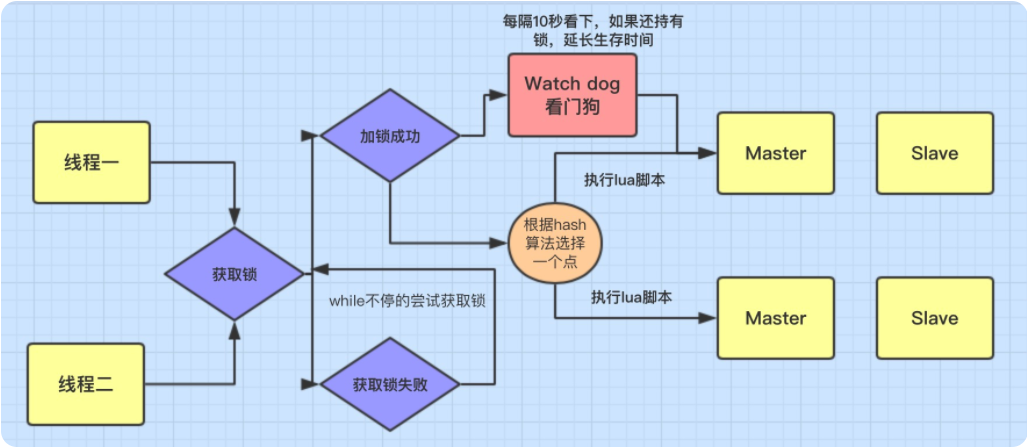
- 可以用Redission来实现分布式锁
- Redission是专门针对Redis分布式锁,提供的一套相关技术
分布式锁的实现原理 #
-
Redis加锁的命令:
SET lock_key random_value NX PX 5000 -
- lock_key:需要加锁的某一个key
- random_value:给key设置一个默认值,因为在Redis中key-value,任意值都可以
-
- NX:加锁命令,生效的地方:有且仅当key不存在,才可以上锁成功
- PX 5000:设定锁的到期时间,单位是毫秒
使用Reids,自己进行实现 #
@PostMapping("/shopAndReduceStoreRedis")
public ResultVO shopAndReduceStore(){
ResultVO resultVO = null;
//time为锁的释放时间,如果达到3秒,那么会自动释放锁
Long time = 3000L;
//设置效果相当于redis命令setnx lock lock,如果当前的key存在,那么无法复制和创建,返回false
Boolean addLockSuccess = redisTemplate.opsForValue().setIfAbsent("lock", "lock",time,TimeUnit.SECONDS);
//判断是否成功添加锁,如果没有,则循环,直到成功添加锁
while (!addLockSuccess){
addLockSuccess = redisTemplate.opsForValue().setIfAbsent("lock", "lock",time,TimeUnit.SECONDS);
//等待一会儿再尝试
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
//守护线程,对主线程进行续命
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
sleep(time/2);
redisTemplate.expire("lock",time/2,TimeUnit.SECONDS);
}
});
thread.setDaemon(true);
thread.start();
try {
Integer store = (Integer) redisTemplate.opsForValue().get("store");
if (store == 0){
resultVO = ResultVO.fail("库存不足");
}else {
redisTemplate.opsForValue().set("store",store--);
resultVO = ResultVO.success("购买成功");
}
}catch (Exception e){
e.printStackTrace();
resultVO = ResultVO.fail("购买异常!");
}finally {
//释放锁
redisTemplate.delete("lock");
return resultVO;
}
}
使用Redission实现 #
1、导入依赖 #
<!-- 导入Redisson分布锁技术 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>
2、编写Redission的配置类 #
/**
* Redisson配置类
* 主要提供:Redis分布式锁的功能
*/
@Configuration
public class RedissonConfiguration {
/**
* 根据配置信息,产生一个Redisson的客户端对象
* @return
*/
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
config.useSingleServer().setAddress("redis://localhost:6379");
return Redisson.create(config);
}
}
3、代码中具体使用 #
@Resource
private RedissonClient redissonClient;
@PostMapping("/shopAndReduceStore")
public ResultVO shopAndReduceStore(){
RLock lock = null;
ResultVO resultVO = null;
try {
//获取锁对象
lock = redissonClient.getLock("lock");
//加锁,30秒释放锁,防止死锁出现
lock.lock(30L, TimeUnit.SECONDS);
Integer store = (Integer) redisTemplate.opsForValue().get("store");
if (store == 0){
resultVO = ResultVO.fail("库存不足");
}else {
redisTemplate.opsForValue().set("store",store--);
resultVO = ResultVO.success("购买成功");
}
}catch (Exception e){
e.printStackTrace();
resultVO = ResultVO.fail("购买异常!");
}finally {
//释放锁
lock.unlock();
return resultVO;
}
}