并发编程概念 #
并发从程序设计的角度,就是希望通过某些机制让计算机可以在一个时间段内,执行多个任务。让一个或多个物理 CPU 在多个程序之间多路复用,提高对计算机资源的利用率。
Go 语言通过编译器运行时(runtime),从语言上支持了并发的特性。Go 语言的并发通过 goroutine 特性完成。goroutine 类似于线程,但是可以根据需要创建多个 goroutine 并发工作**。goroutine 是由 Go 语言的运行时调度完成,而线程是由操作系统调度完成。**
并发编程实现模型 #
并发模型一般分为:多进程编程、多线程编程、非阻塞/异步 IO 编程以及基于协程的编程。
- 多进程
- 多进程是在操作系统层面进行并发的基本模式。同时也是开销最大的模式。在Linux平台上,很多工具链正是采用这种模式在工作。
- 比如某个 Web 服务器,它会有专门的进程负责网络端口的监听和链接管理,还会有专门的进程负责事务和运算。这种方法的好处在于简单、进程间互不影响,坏处在于系统开销大,因为所有的进程都是由内核管理的。
- 多线程
- 在大部分操作系统上都属于系统层面的并发模式,也是我们使用最多的最有效的一种模式。目前,我们所见的几乎所有工具链都会使用这种模式。它比多进程的开销小很多,但是其开销依旧比较大,且在高并发模式下,效率会有影响。
- 基于回调的非阻塞/异步 IO
- 这种架构的诞生实际上来源于多线程模式的危机。在很多高并发服务器开发实践中,使用多线程模式会很快耗尽服务器的内存和 CPU 资源。
- 而这种模式通过事件驱动的方式使用异步 IO,使服务器持续运转,且尽可能地少用线程,降低开销,它目前在 Node.js 中得到了很好的实践。但是使用这种模式,编程比多线程要复杂,因为它把流程做了分割,对于问题本身的反应不够自然。
- 协程
- 协程(Coroutine)本质上是一种用户态线程,不需要操作系统来进行抢占式调度,且在真正的实现中寄存于线程中,因此,系统开销极小,可以有效提高线程的任务并发性,而避免多线程的缺点。
- 使用协程的优点是编程简单,结构清晰;缺点是需要语言的支持,如果不支持,则需要用户在程序中自行实现调度器。目前,原生支持协程的语言还很少。
常见概念 #
- 进程/线程
- 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。
- 线程是进程的一个执行实体,是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。
- 一个进程可以创建和撤销多个线程,同一个进程中的多个线程之间可以并发执行。
- 并发/并行
- 多线程程序在单核心的 cpu 上运行,也就是没有真正意义上同时执行,称为并发;多线程程序在多核心的 cpu 上运行,称为并行。
- 并发与并行并不相同,并发主要由切换时间片来实现“同时”运行,并行则是直接利用多核实现多线程的运行,Go程序可以设置使用核心数,以发挥多核计算机的能力。
- 协程/线程
- 协程:独立的栈空间,共享堆空间,调度由用户自己控制,本质上有点类似于用户级线程(即go中的goroutine,轻量级线程),这些用户级线程的调度也是自己实现的。
- 线程:一个线程上可以跑多个协程,协程是轻量级的线程。
goroutine与线程的区别 #
- 极低的创建和切换成本
- goroutine的初始栈大小仅有2KB(Go 1.18后为2KB,此前是8KB)
- 而线程的栈通常是MB级别
- 动态栈大小
- goroutine的栈大小可以根据需要动态增长和收缩
- 最大可达1GB(64位系统)
- 高效的调度模型
- Go运行时实现了M:N的调度模型
- 多个goroutine(N)可以在少量系统线程(M)上运行
- 避免了上下文切换的高成本
- 与线程的数量对比
- 系统可以轻松支持数十万甚至数百万的goroutine同时运行
- 创建同等数量的线程会耗尽系统资源
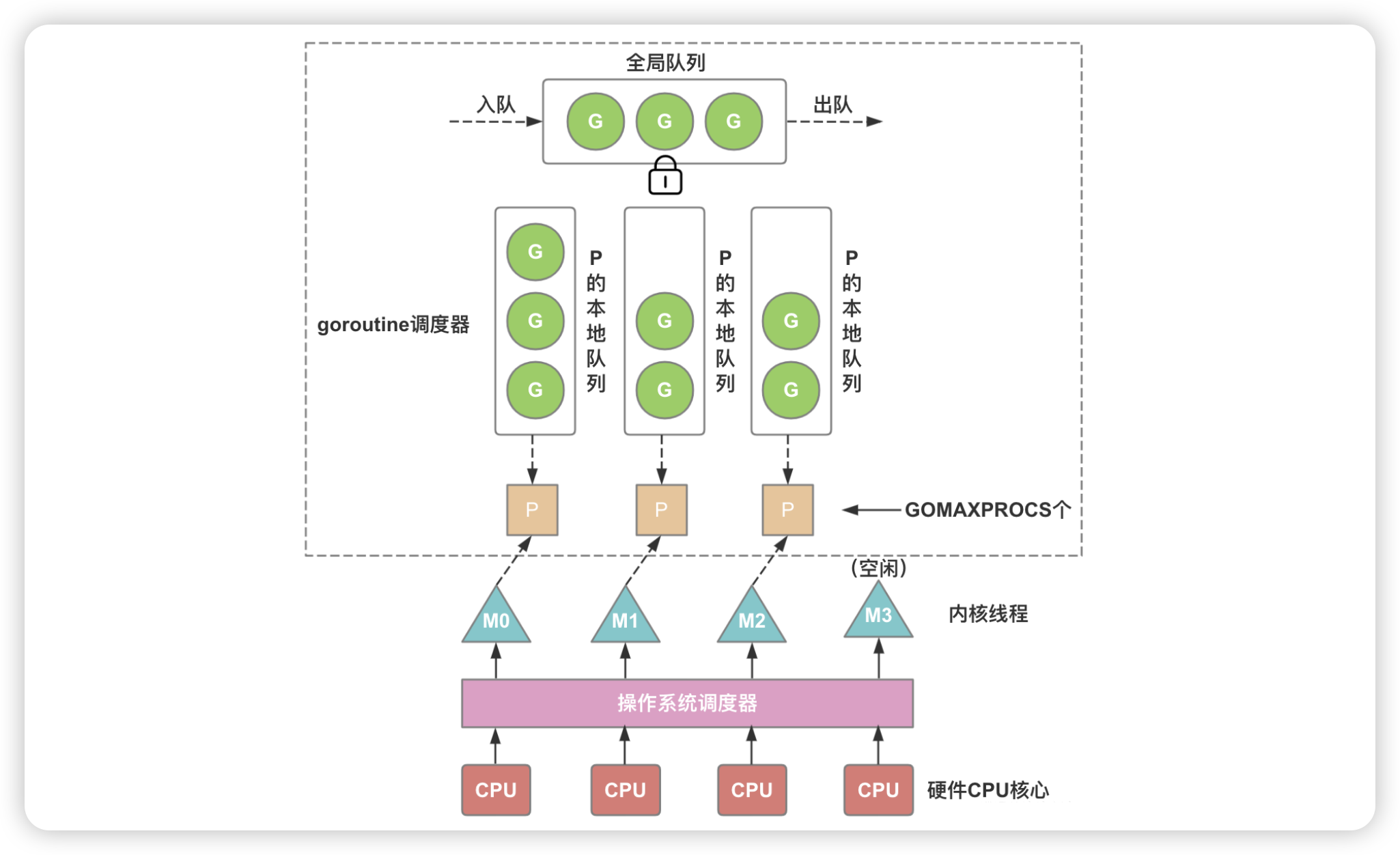
GMP模型 #
Go调度器基于GMP模型工作
- G:goroutine,Go协程,是参与调度与执行的最小单位
- M:machine,操作系统线程
- P::processor,调度上下文,负责连接M和G
CSP 模型 #
Go的并发哲学基于CSP(Communicating Sequential Processes,通信顺序进程)模型。
CSP原则 #
CSP模型的核心思想是:不要通过共享内存来通信,而要通过通信来共享内存
这一原则鼓励通过显式的消息传递(channel)而非共享状态来协调并发执行,从而减少锁和同步原语的使用。
并发模式对比 #
| 模式 | 特点 | 典型语言/库 |
|---|---|---|
| 多线程共享内存 | 使用锁保护共享状态 | Java, C++ |
| Actor模型 | 独立actors通过消息通信 | Erlang, Akka |
| CSP模型 | 通过通道协调并发进程 | Go |
goroutine #
goroutine 是协程的 Go 语言实现,它是语言原生支持的,相对于一般由库实现协程的方式,goroutine 更加强大,它的调度一定程度上是由 go 运行时(runtime)管理。
其好处之一是,当某 goroutine 发生阻塞时(例如同步IO操作等),会自动出让 CPU 给其它 goroutine。
goroutine是非常轻量级的,它就是一段代码,一个函数入口,以及在堆上为其分配的一个堆栈(初始大小为4K,会随着程序的执行自动增长删除)。所以它非常廉价,我们可以很轻松的创建上万个 goroutine。
Go 程序从 main 包的 main() 函数开始,在程序启动时,Go 程序就会为 main() 函数创建一个默认的 goroutine。
启动与调度 #
启动 #
package main
import (
"fmt"
"time"
)
func sayHello() {
fmt.Println("Hello from goroutine!")
}
func main() {
// 启动一个goroutine
go sayHello()
// 防止主goroutine退出太快
time.Sleep(100 * time.Millisecond)
fmt.Println("Main function finished")
}
go sayHello()启动了一个新的goroutine执行sayHello函数- 主函数不会等待goroutine完成,需要通过
time.Sleep让主goroutine等待
调度时机 #
Go运行时会在以下情况触发goroutine调度:
- 系统调用:当goroutine执行系统调用时(如I/O操作)
- 通道操作:在channel上的发送和接收操作可能导致阻塞
- 垃圾回收:GC工作时可能触发调度
- 显式调用:通过
runtime.Gosched()主动让出CPU - 等待锁:当争用
sync包中的互斥锁时 - 函数调用:当函数调用太深且栈需要扩容时
如下,则是主动让出 CPU
package main
import (
"fmt"
"runtime"
)
func main() {
go func() {
for i := 0; i < 3; i++ {
fmt.Println("Goroutine:", i)
}
}()
for i := 0; i < 3; i++ {
// 让出CPU,给其他goroutine执行的机会
runtime.Gosched()
fmt.Println("Main:", i)
}
}
channel #
channel是Go语言提供的一种数据结构,它像一个管道,可以在不同的goroutine之间安全地传递数据。channel有以下特点:
- 类型安全:每个channel只能传递指定类型的数据
- 并发安全:channel的操作是原子的,不需要额外的锁
- FIFO顺序:数据按照先进先出的顺序从channel中读取
- 阻塞机制:可以用于goroutine之间的同步
从本质上讲,channel是一个数据结构,内部包含一个缓冲区、一个互斥锁以及两个等待队列(发送者队列和接收者队列)。
为什么需要channel #
在并发编程中,我们通常需要解决以下问题:
- 数据共享:多个goroutine需要安全地共享数据
- 工作分发:将任务分配给多个worker goroutine
- 信号通知:发送事件信号(如完成、取消等)
- 同步控制:协调不同goroutine的执行顺序
传统的共享内存并发模型通常使用锁来解决这些问题,但锁机制容易导致复杂性增加、死锁和性能问题。channel提供了一种更简洁、更符合Go语言哲学的方案。
声明和创建 #
定义一个 channel 时,也需要定义发送到 channel 的值的类型,注意,chan 类型的空值是 nil,必须使用 make 创建 channel
// 声明,chanName:通道变量名称,chanType:通道内的数据类型
var chanName chan chanType
// 声明并定义
var chanName chan chanType := make(chan chanType)
// 声明并定义,使用自动类型推导
chanName := make(chan chanType)
// 例子
var c chan int = make(chan int)
c := make(chan int)
c := make(chan string)
关闭通道 #
关闭 channel 非常简单,直接使用Go语言内置的 close() 函数即可
close(chName)
关闭channel时应遵循以下原则:
- 发送方负责关闭:通常,发送数据的一方应该负责关闭channel
- 不要关闭只接收的channel:从类型安全的角度,不应该关闭只接收的channel
- 使用defer关闭:在适当的地方使用defer确保channel被关闭
- 不确定时不要关闭:如果不确定是否需要关闭,或者不知道何时关闭,可以不关闭它
发送和接收 #
通道创建后,就可以使用通道进行发送和接收操作。
发送 #
通道的发送使用特殊的操作符<-,将数据通过通道发送的格式为:
chanName <- value
- chanName:通过make创建好的通道实例。
- value:可以是变量、常量、表达式或者函数返回值等。值的类型必须与ch通道的元素类型一致。
把数据往通道中发送时,如果接收方一直都没有接收,那么发送操作将持续阻塞。Go 程序运行时能智能地发现一些永远无法发送成功的语句并做出提示,例如,现在创建一个chan,但是没有接收方:
package main
func main() {
ch := make(chan string)
ch <- "hello"
}
/*
fatal error: all goroutines are asleep - deadlock!
*/
运行时发现所有的 goroutine(包括main)都处于等待 goroutine。也就是说所有 goroutine 中的 channel 并没有形成发送和接收对应的代码。
接收 #
- 通道的收发操作在不同的两个 goroutine 间进行。
- 由于通道的数据在没有接收方处理时,数据发送方会持续阻塞,因此通道的接收必定在另外一个 goroutine 中进行。
- 接收将持续阻塞直到发送方发送数据。
- 如果接收方接收时,通道中没有发送方发送数据,接收方也会发生阻塞,直到发送方发送数据为止。
- 每次接收一个元素。
- 通道一次只能接收一个数据元素。
阻塞接收数据 #
阻塞模式接收数据时,将接收变量作为<-操作符的左值,执行该语句时将会阻塞,直到接收到数据并赋值给 value变量。
value := <-chanName
阻塞接收数据后,忽略从通道返回的数据,执行该语句时将会发生阻塞,直到接收到数据,但接收到的数据会被忽略。这个方式实际上只是通过通道在 goroutine 间阻塞收发实现并发同步。
<-chanName
非阻塞接收数据 #
使用非阻塞方式从通道接收数据时,语句不会发生阻塞,非阻塞的通道接收方法可能造成高的 CPU 占用,因此使用非常少。
value, ok := <-chanName
/*
value:表示接收到的数据。未接收到数据时,value 为通道类型的零值。
ok:表示是否接收到数据,false表示通道已经关闭且为空
*/
循环接收 #
通道的数据接收可以借用 for range 语句进行多个元素的接收操作,使用后所在的goroutine将会阻塞循环接收
ch := make(chan int, 3)
go func() {
ch <- 1
ch <- 2
ch <- 3
close(ch) // 必须关闭,否则下面的range循环会死锁
}()
for v := range ch {
fmt.Println(v)
}
单向通道 #
所谓的单向 channel 概念,其实只是对 channel 的一种使用限制,比如限制一个通道在这个函数中的读写,因此,单向通道有利于代码接口的严谨性。
// 只写的通道
var chanName chan<- chanType
// 只读的通道
var chanName <-chan chanType
类型转换关系
- 双向channel可以转换为单向channel,但反之不行
- 这种转换通常用于函数参数,限制函数对channel的操作
func send(ch chan<- int) {
ch <- 42 // 只能发送
// <-ch // 编译错误:不能从只发送channel接收
}
func receive(ch <-chan int) {
v := <-ch // 只能接收
// ch <- 42 // 编译错误:不能向只接收channel发送
}
func main() {
ch := make(chan int) // 双向channel
go send(ch) // 可以将双向channel传给只发送channel参数
go receive(ch) // 可以将双向channel传给只接收channel参数
}
无缓冲与缓冲channel #
无缓冲通道 #
Go语言中无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。这种类型的通道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。
如果两个 goroutine 没有同时准备好,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
- 阻塞指的是由于某种原因数据没有到达,当前协程(线程)持续处于等待状态,直到条件满足才解除阻塞。
- 同步指的是在两个或多个协程(线程)之间,保持数据内容一致性的机制。
创建无缓冲的通道 #
chanName := make(chan chanType)
chanName := make(chan chanType,0) // 显式指定缓冲大小为0
缓冲通道 #
Go语言中有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个值的通道。这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也会不同。只有在通道中没有要接收的值时,接收动作才会阻塞。只有在通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同**:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。**
在无缓冲通道的基础上,为通道增加一个有限大小的存储空间形成带缓冲通道。带缓冲通道在发送时无需等待接收方接收即可完成发送过程,并且不会发生阻塞,只有当存储空间满时才会发生阻塞。同理,如果缓冲通道中有数据,接收时将不会发生阻塞,直到通道中没有数据可读时,通道将会再度阻塞。
创建带缓冲的通道 #
chanName := make(chan chanType,size)
/*
chanName:通道实例变量名
chanType:通道所内数据类型
size:通道缓冲区大小
*/
select 语句 #
工作原理 #
- 评估所有channel表达式:首先计算所有case中的channel表达式
- 评估所有发送/接收操作:尝试在所有channel上执行发送或接收操作
- 阻塞或执行:
- 如果有一个或多个case准备好(可发送或可接收),Go会随机选择一个执行
- 如果没有case准备好且有default分支,则执行default分支
- 如果没有case准备好且没有default分支,则select语句阻塞,直到某个case准备好
语法 #
select {
case <-ch1:
// 如果从ch1成功接收数据,则执行此分支
case ch2 <- value:
// 如果成功向ch2发送数据,则执行此分支
case x := <-ch3:
// 如果从ch3成功接收数据,则执行此分支,并将接收的值赋给x
default:
// 如果上面的case都没有准备好,则执行此分支(可选)
}
特性与规则 #
- 随机选择:当多个case同时准备好时,select会随机选择一个执行,这避免了固定顺序可能导致的饥饿问题
- 零case:空的select语句(
select{})会永远阻塞 - 无匹配死锁检测:如果select语句中没有default分支,且所有case都阻塞,则当前goroutine会被阻塞;如果所有goroutine都被阻塞,Go运行时会检测到死锁并报错
- default避免阻塞:包含default分支的select语句永远不会阻塞
channel 应用场景 #
信号通知 #
使用channel发送信号通知其他goroutine某个事件已经发生
func worker(done chan struct{}) {
fmt.Println("工作开始...")
time.Sleep(3 * time.Second)
fmt.Println("工作完成")
done <- struct{}{} // 发送完成信号
}
func main() {
done := make(chan struct{})
go worker(done)
<-done // 等待工作完成
fmt.Println("收到完成信号,主程序继续执行")
}
控制超时 #
结合select和time.After实现超时控制:
func main() {
ch := make(chan string)
go func() {
time.Sleep(2 * time.Second)
ch <- "操作完成"
}()
select {
case result := <-ch:
fmt.Println(result)
case <-time.After(1 * time.Second):
fmt.Println("操作超时")
}
}
工作池模式 #
使用带缓冲的channel实现工作池,限制并发数量
func worker(id int, jobs <-chan int, results chan<- int) {
for job := range jobs {
fmt.Printf("worker %d started job %d\n", id, job)
time.Sleep(time.Second) // 模拟工作耗时
fmt.Printf("worker %d finished job %d\n", id, job)
results <- job * 2
}
}
func main() {
jobs := make(chan int, 100)
results := make(chan int, 100)
// 启动3个worker
for w := 1; w <= 3; w++ {
go worker(w, jobs, results)
}
// 发送9个任务
for j := 1; j <= 9; j++ {
jobs <- j
}
close(jobs)
// 收集结果
for a := 1; a <= 9; a++ {
<-results
}
}
流水线模式 #
使用channel组合多个处理阶段,形成数据流水线:
func generator(nums ...int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for _, n := range nums {
out <- n
}
}()
return out
}
func square(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
out <- n * n
}
}()
return out
}
func main() {
// 组合成处理流水线: generator -> square -> consumer(打印)
for n := range square(generator(1, 2, 3, 4, 5)) {
fmt.Println(n)
}
}
sync 包 #
上面的goroutine和channel。这些机制主要基于CSP(通信顺序进程)模型,强调"通过通信来共享内存"。然而,在某些情况下,我们需要直接控制对共享资源的访问。这时,Go语言标准库中的sync包就派上用场了。
Mutex(互斥锁) #
Mutex提供了一种互斥机制,确保同一时间只有一个goroutine可以访问共享资源。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var mutex sync.Mutex
counter := 0
// 并发更新counter
var wg sync.WaitGroup
for i := 0; i < 1000; i++ {
wg.Add(1)
go func() {
defer wg.Done()
mutex.Lock() // 加锁
defer mutex.Unlock() // 解锁
counter++
}()
}
wg.Wait()
fmt.Println("计数器最终值:", counter) // 输出: 计数器最终值: 1000
}
常用方法 #
Lock():获取锁。如果锁已被其他goroutine获取,则阻塞直到锁可用Unlock():释放锁。应在与Lock()相同的goroutine中调用TryLock():(Go 1.18+)尝试获取锁,如果锁不可用则立即返回false而不阻塞
注意点 #
- 总是使用
defer mutex.Unlock()确保锁被释放 - 尽量减小临界区(加锁和解锁之间的代码)
- 避免在持有锁的情况下调用可能阻塞的操作
- 不要在goroutine A中锁定,然后在goroutine B中解锁
RWMutex(读写锁) #
RWMutex允许多个读操作并发执行,但写操作是互斥的。当有写锁时,所有的读操作都会被阻塞。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var rwMutex sync.RWMutex
data := make(map[string]string)
// 写入操作
go func() {
for i := 0; i < 10; i++ {
rwMutex.Lock() // 写锁
key := fmt.Sprintf("key%d", i)
data[key] = fmt.Sprintf("value%d", i)
time.Sleep(100 * time.Millisecond) // 模拟写入耗时
rwMutex.Unlock()
time.Sleep(200 * time.Millisecond) // 给读操作时间
}
}()
// 多个并发读取操作
var wg sync.WaitGroup
for r := 0; r < 5; r++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
for i := 0; i < 10; i++ {
rwMutex.RLock() // 读锁
for k, v := range data {
fmt.Printf("读取者 %d: %s = %s\n", id, k, v)
}
rwMutex.RUnlock()
time.Sleep(150 * time.Millisecond)
}
}(r)
}
wg.Wait()
}
常用方法 #
Lock()/Unlock():获取/释放写锁。与Mutex相同,写操作是互斥的RLock()/RUnlock():获取/释放读锁。多个goroutine可以同时持有读锁TryLock()/TryRLock():(Go 1.18+)尝试获取写锁/读锁,非阻塞
使用场景 #
当共享资源的读操作远多于写操作时,RWMutex比Mutex更有效。例如:
- 配置信息:频繁读取,偶尔更新
- 缓存系统:大量读取,少量写入
- 统计数据:持续读取,定期更新
WaitGroup(等待组) #
WaitGroup用于等待一组goroutine完成执行。它提供了一种简单的方式来协调多个并发操作的完成。
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, wg *sync.WaitGroup) {
defer wg.Done() // 工作完成时通知WaitGroup
fmt.Printf("Worker %d starting\n", id)
time.Sleep(time.Second) // 模拟工作
fmt.Printf("Worker %d done\n", id)
}
func main() {
var wg sync.WaitGroup
// 启动5个worker
for i := 1; i <= 5; i++ {
wg.Add(1) // 增加计数器
go worker(i, &wg)
}
// 等待所有worker完成
wg.Wait()
fmt.Println("All workers completed")
}
常用方法 #
Add(delta int):增加WaitGroup的计数器值Done():减少WaitGroup的计数器值,相当于Add(-1)Wait():阻塞直到计数器变为0
注意点 #
- 正确设置计数器:在启动goroutine之前调用
Add() - 总是通过指针传递WaitGroup:WaitGroup不应被复制
- 使用defer语句确保
Done()被调用
Once(只被执行一次) #
Once用于确保某个函数只被执行一次,即使在多个goroutine中并发调用也是如此。它通常用于单例模式、延迟初始化或执行只需要一次的设置操作。
在下面例子中,尽管有10个goroutine尝试执行初始化函数,但once.Do()确保只有一个goroutine能够执行它。
package main
import (
"fmt"
"sync"
)
func main() {
var once sync.Once
done := make(chan bool)
// 尝试在多个goroutine中执行初始化
for i := 0; i < 10; i++ {
go func(id int) {
fmt.Printf("Goroutine %d trying to initialize\n", id)
once.Do(func() {
fmt.Printf("Initialization done by goroutine %d\n", id)
})
done <- true
}(i)
}
// 等待所有goroutine完成
for i := 0; i < 10; i++ {
<-done
}
}
特性与限制 #
- Once实例只能用于执行一个指定的函数一次
- 如果需要确保多个不同的函数都只执行一次,需要为每个函数创建单独的Once实例
- 一旦
Do()方法完成调用,对同一个Once实例的后续Do()调用将不会执行提供的函数 - 如果在
Do()调用的函数中发生panic,Once将认为操作已完成 - Once没有重置机制,一旦使用就不能重新使用
Cond(条件变量) #
Cond实现了一个条件变量,它是等待或宣布事件发生的goroutine的会合点。它允许goroutine等待某个条件成立,然后在条件成立时得到通知。
基本概念 #
条件变量总是与互斥锁关联,并通过锁来保护条件的检查和更新。Cond提供了三个主要方法:
Wait():释放关联的锁,等待通知,被唤醒后重新获取锁Signal():唤醒一个等待的goroutineBroadcast():唤醒所有等待的goroutine
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var mu sync.Mutex
cond := sync.NewCond(&mu)
ready := false
// 消费者goroutine
for i := 0; i < 3; i++ {
go func(id int) {
mu.Lock()
defer mu.Unlock()
fmt.Printf("Consumer %d is waiting...\n", id)
for !ready { // 使用循环检查条件
cond.Wait() // 等待信号
}
fmt.Printf("Consumer %d received signal\n", id)
}(i)
}
// 给消费者一点时间启动
time.Sleep(time.Second)
// 生产者goroutine
go func() {
mu.Lock()
defer mu.Unlock()
fmt.Println("Producer is ready")
ready = true
fmt.Println("Producer broadcasts signal")
cond.Broadcast() // 通知所有等待的goroutine
}()
// 等待足够时间让所有goroutine完成
time.Sleep(3 * time.Second)
}
在上面的例子中:
- 多个消费者goroutine等待
ready条件变为true - 每个消费者获取锁,检查条件,如果不满足则调用
Wait()等待 - 生产者将条件设置为true,然后调用
Broadcast()通知所有等待的消费者 - 所有消费者被唤醒,重新获取锁,再次检查条件,然后继续执行
使用模式 #
- 始终在循环中使用Wait():这是避免虚假唤醒的重要模式
- Signal vs Broadcast:选择适当的通知机制
Signal():唤醒单个等待者,适用于任务队列等场景,只需一个工作者处理Broadcast():唤醒所有等待者,适用于状态变化等场景,需要所有人都知道
- 确保锁的正确使用:在调用Signal或Broadcast时通常需要持有锁
Pool #
sync.Pool提供了一个可以重复使用临时对象的池,有助于减少垃圾回收压力,特别是在高并发环境下。
基本概念 #
Pool的主要特性:
- 线程安全:可以在多个goroutine之间共享
- 无容量限制:可以存储任意数量的对象
- 临时存储:池中的对象可能在任何时候被自动移除(特别是在GC发生时)
- 高效复用:避免频繁分配和回收对象,减轻GC压力
常用方法 #
Pool提供了两个主要方法:
Get() interface{}:从池中获取对象。如果池为空,则调用New函数创建一个新对象Put(x interface{}):将对象放回池中以供后续重用
package main
import (
"bytes"
"fmt"
"sync"
)
func main() {
// 创建一个池,用于复用bytes.Buffer
var bufferPool = sync.Pool{
New: func() interface{} {
fmt.Println("Creating a new buffer")
return new(bytes.Buffer)
},
}
// 获取一个Buffer
buffer1 := bufferPool.Get().(*bytes.Buffer)
buffer1.WriteString("Hello")
fmt.Println("Buffer1:", buffer1.String())
// 清空并放回池中
buffer1.Reset()
bufferPool.Put(buffer1)
// 获取一个Buffer(可能是刚才放回的那个)
buffer2 := bufferPool.Get().(*bytes.Buffer)
buffer2.WriteString("World")
fmt.Println("Buffer2:", buffer2.String())
// 清空并放回池中
buffer2.Reset()
bufferPool.Put(buffer2)
// 同时获取多个Buffer
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
// 获取Buffer
buf := bufferPool.Get().(*bytes.Buffer)
// 使用Buffer
buf.WriteString(fmt.Sprintf("Goroutine %d", id))
fmt.Printf("Goroutine %d: %s\n", id, buf.String())
// 清空并放回
buf.Reset()
bufferPool.Put(buf)
}(i)
}
wg.Wait()
}
并发模式 #
并发模式是在并发环境中解决特定问题的常见结构和方法。就像设计模式帮助我们组织代码一样,并发模式帮助我们组织并发逻辑,使其更易于理解、测试和维护。
好的并发模式应该具备以下特点:
- 清晰的责任边界
- 良好的错误处理
- 可控的资源使用
- 优雅的终止机制
掌握并发模式有以下好处:
- 提高代码质量和可维护性
- 减少并发错误(如死锁、竞态条件)
- 提高性能和资源利用率
- 简化复杂并发逻辑的实现
- 使代码更加模块化和可重用
生产者-消费者模式 #
生产者-消费者是最基本也是最常用的并发模式之一。它将"生产数据"和"消费数据"的过程解耦,通过channel在两者之间传递数据。
package main
import (
"fmt"
"sync"
"time"
)
func producer(jobs chan<- int) {
defer close(jobs)
for i := 1; i <= 5; i++ {
fmt.Printf("生产任务: %d\n", i)
jobs <- i
time.Sleep(time.Millisecond * 500)
}
}
func consumer(id int, jobs <-chan int, wg *sync.WaitGroup) {
defer wg.Done()
for job := range jobs {
fmt.Printf("消费者 %d 处理任务: %d\n", id, job)
time.Sleep(time.Second) // 模拟处理时间
}
}
func main() {
jobs := make(chan int, 3)
var wg sync.WaitGroup
// 启动一个生产者
go producer(jobs)
// 启动两个消费者
for i := 1; i <= 2; i++ {
wg.Add(1)
go consumer(i, jobs, &wg)
}
wg.Wait()
fmt.Println("所有工作完成")
}
这个例子展示了生产者-消费者模式的基本用法:
- 生产者生成任务并发送到channel
- 多个消费者从channel接收任务并处理
- 生产者完成后关闭channel
- 主goroutine等待所有消费者完成
带错误处理的生产者-消费者 #
现实应用中,我们通常需要处理错误:
- 使用结构体传递任务和结果,包含错误信息
- 在消费者中处理生产者可能产生的错误
- 消费者也可能产生错误,并传递给结果收集者
- 主goroutine处理并整理所有结果
package main
import (
"errors"
"fmt"
"sync"
"time"
)
type Job struct {
ID int
Err error
}
type Result struct {
JobID int
Value string
Err error
}
func producer(jobs chan<- Job) {
defer close(jobs)
for i := 1; i <= 5; i++ {
var err error
if i == 3 {
err = errors.New("模拟生产错误")
}
jobs <- Job{ID: i, Err: err}
time.Sleep(time.Millisecond * 500)
}
}
func consumer(jobs <-chan Job, results chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
for job := range jobs {
if job.Err != nil {
results <- Result{JobID: job.ID, Err: job.Err}
continue
}
// 模拟处理
time.Sleep(time.Second)
var err error
if job.ID == 4 {
err = errors.New("模拟处理错误")
}
result := Result{
JobID: job.ID,
Value: fmt.Sprintf("处理结果 %d", job.ID),
Err: err,
}
results <- result
}
}
func main() {
jobs := make(chan Job, 5)
results := make(chan Result, 5)
var wg sync.WaitGroup
// 启动生产者
go producer(jobs)
// 启动消费者
for i := 1; i <= 3; i++ {
wg.Add(1)
go consumer(jobs, results, &wg)
}
// 收集结果
go func() {
wg.Wait()
close(results)
}()
// 处理结果
for result := range results {
if result.Err != nil {
fmt.Printf("任务 %d 出错: %v\n", result.JobID, result.Err)
continue
}
fmt.Printf("任务 %d 完成: %s\n", result.JobID, result.Value)
}
}
实际应用场景 #
- Web服务器处理请求:传入的HTTP请求作为生产者,工作池作为消费者
- 数据处理管道:从数据源读取数据(生产者),经过多阶段处理(消费者)
- 任务队列:应用程序生成后台任务(生产者),工作者处理任务(消费者)
- 日志处理:应用程序生成日志事件(生产者),日志处理器写入存储(消费者)
工作池模式 (Worker Pool) #
工作池模式是生产者-消费者模式的扩展,它维护一组工作者(goroutine)来处理一系列任务。与简单的生产者-消费者模式相比,工作池模式更强调工作者的管理和任务的分发。
基本工作池的特点:
- 预先创建固定数量的工作者
- 所有工作者共享同一个任务队列
- 任务完成后结果发送到结果队列
- 主程序等待所有工作者完成并收集结果
package main
import (
"fmt"
"sync"
"time"
)
func worker(id int, jobs <-chan int, results chan<- int, wg *sync.WaitGroup) {
defer wg.Done()
for job := range jobs {
fmt.Printf("工作者 %d 开始处理任务 %d\n", id, job)
time.Sleep(time.Second) // 模拟工作耗时
fmt.Printf("工作者 %d 完成任务 %d\n", id, job)
results <- job * 2
}
}
func main() {
const numJobs = 10
const numWorkers = 3
jobs := make(chan int, numJobs)
results := make(chan int, numJobs)
var wg sync.WaitGroup
// 启动工作者
for w := 1; w <= numWorkers; w++ {
wg.Add(1)
go worker(w, jobs, results, &wg)
}
// 发送任务
for j := 1; j <= numJobs; j++ {
jobs <- j
}
close(jobs)
// 等待所有工作者完成
go func() {
wg.Wait()
close(results)
}()
// 收集结果
for result := range results {
fmt.Printf("结果: %d\n", result)
}
}
可限流的工作池 #
在实际应用中,我们可能需要限制并发数量或请求速率:
限流工作池的关键功能:
- 通过令牌桶或其他限流算法控制请求速率
- 过载时请求可以等待或被拒绝
- 防止系统资源过度使用
- 保护下游服务免受突发流量影响
package main
import (
"fmt"
"sync"
"time"
)
type RateLimiter struct {
interval time.Duration
ticker *time.Ticker
stopCh chan struct{}
}
func NewRateLimiter(rps int) *RateLimiter {
interval := time.Second / time.Duration(rps)
return &RateLimiter{
interval: interval,
ticker: time.NewTicker(interval),
stopCh: make(chan struct{}),
}
}
func (rl *RateLimiter) Allow() bool {
select {
case <-rl.ticker.C:
return true
case <-rl.stopCh:
return false
default:
return false
}
}
func (rl *RateLimiter) Stop() {
rl.ticker.Stop()
close(rl.stopCh)
}
func processRequest(id int, limiter *RateLimiter, wg *sync.WaitGroup) {
defer wg.Done()
start := time.Now()
// 等待限流器允许
for !limiter.Allow() {
time.Sleep(time.Millisecond * 10)
}
// 模拟处理请求
time.Sleep(time.Millisecond * 50)
fmt.Printf("请求 %d 处理完成,等待时间: %v\n", id, time.Since(start))
}
func main() {
// 每秒5个请求
limiter := NewRateLimiter(5)
defer limiter.Stop()
var wg sync.WaitGroup
// 模拟20个并发请求
for i := 1; i <= 20; i++ {
wg.Add(1)
go processRequest(i, limiter, &wg)
}
wg.Wait()
fmt.Println("所有请求处理完成")
}
实际应用场景 #
- API服务器:控制对数据库或第三方服务的请求速率
- 批量数据处理:处理大量数据时限制内存使用
- 爬虫系统:控制爬取速率,避免对目标站点造成压力
- 任务调度系统:管理和分配计算密集型任务
- 微服务通信:限制服务间的调用流量
管道模式 (Pipeline) #
管道模式将数据处理分成多个阶段,每个阶段通过channel连接起来。这种模式特别适合处理数据流,每个阶段都可以并发执行。
基本管道模式的特点:
- 每个阶段是一个函数,接收上一阶段的输出作为输入
- 每个阶段在单独的goroutine中运行
- 阶段间通过channel传递数据
- 当输入channel关闭且处理完所有数据时,该阶段关闭其输出channel
package main
import (
"fmt"
)
// 生成器:生成整数
func generator(nums ...int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for _, n := range nums {
out <- n
}
}()
return out
}
// 平方:计算输入值的平方
func square(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
out <- n * n
}
}()
return out
}
// 过滤:只保留奇数
func onlyOdd(in <-chan int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for n := range in {
if n%2 != 0 {
out <- n
}
}
}()
return out
}
func main() {
// 构建管道
nums := generator(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
squares := square(nums)
odds := onlyOdd(squares)
// 消费结果
for odd := range odds {
fmt.Println(odd)
}
}
带错误处理的管道 #
实际应用中,我们需要处理每个管道阶段可能出现的错误:
带错误处理的管道特点:
- 每个结果包含值和可能的错误
- 一旦发生错误,错误会沿管道传播
- 管道后期阶段可以选择如何处理错误(传递、处理或停止)
- 主函数可以收集处理所有错误
package main
import (
"errors"
"fmt"
)
type Result struct {
Value int
Err error
}
func generator(nums ...int) <-chan Result {
out := make(chan Result)
go func() {
defer close(out)
for _, n := range nums {
if n < 0 {
out <- Result{Err: errors.New("负数不被允许")}
return
}
out <- Result{Value: n}
}
}()
return out
}
func square(in <-chan Result) <-chan Result {
out := make(chan Result)
go func() {
defer close(out)
for res := range in {
if res.Err != nil {
out <- res // 传递错误
continue
}
out <- Result{Value: res.Value * res.Value}
}
}()
return out
}
func main() {
// 构建管道
values := generator(1, 2, 3, -4, 5)
squares := square(values)
// 消费结果
for res := range squares {
if res.Err != nil {
fmt.Printf("错误: %v\n", res.Err)
continue
}
fmt.Println(res.Value)
}
}
管道模式的优势与实际应用 #
管道模式的主要优势:
- 模块化:每个处理阶段都是独立的,易于测试和维护
- 并发处理:各阶段可以并行执行,提高吞吐量
- 解耦:数据生产和消费解耦,提高代码可读性
- 灵活组合:可以根据需要动态组合不同处理阶段
实际应用场景:
- ETL处理:数据提取、转换和加载过程
- 图像处理:图像加载、缩放、滤镜应用等多步骤处理
- 数据分析:数据读取、清洗、聚合、分析的流水线
- 实时数据流处理:日志分析、事件处理等
扇入扇出模式 (Fan-in/Fan-out) #
扇出是将任务分配给多个worker并行处理,扇入是将多个结果汇总到一个channel。这种模式适合处理可以并行的任务,然后需要汇总结果的场景。
扇入扇出模式的关键组件:
- 扇出:将一个任务分配给多个worker并行处理
- worker:每个worker独立处理分配给它的任务
- 扇入:将多个worker的结果合并到一个channel
package main
import (
"fmt"
"sync"
)
// 扇出:将一个输入拆分为多个并行处理
func fanOut(in <-chan int, numWorkers int) []<-chan int {
outputs := make([]<-chan int, numWorkers)
for i := 0; i < numWorkers; i++ {
outputs[i] = processWorker(in, i)
}
return outputs
}
// 扇入:将多个输入合并到一个输出
func fanIn(inputs []<-chan int) <-chan int {
var wg sync.WaitGroup
out := make(chan int)
// 为每个输入启动一个goroutine
for _, input := range inputs {
wg.Add(1)
go func(ch <-chan int) {
defer wg.Done()
for val := range ch {
out <- val
}
}(input)
}
// 当所有输入处理完毕后关闭输出
go func() {
wg.Wait()
close(out)
}()
return out
}
// 工作者:处理输入并产生输出
func processWorker(in <-chan int, workerID int) <-chan int {
out := make(chan int)
go func() {
defer close(out)
for val := range in {
// 模拟处理:计算平方
result := val * val
fmt.Printf("工作者 %d 处理 %d -> %d\n", workerID, val, result)
out <- result
}
}()
return out
}
func main() {
// 创建输入
input := make(chan int)
go func() {
defer close(input)
for i := 1; i <= 10; i++ {
input <- i
}
}()
// 扇出:分配给3个工作者
workers := fanOut(input, 3)
// 扇入:汇总所有结果
results := fanIn(workers)
// 处理最终结果
var sum int
for res := range results {
sum += res
}
fmt.Printf("所有结果的总和: %d\n", sum)
}
应用场景 #
扇入扇出模式在以下场景特别有用:
- 并行计算:将大型计算任务拆分为多个子任务并行处理
- 数据聚合:从多个源收集数据并合并结果
- 并行API请求:同时发起多个API请求,然后合并响应
- 分布式系统:分散工作负载,然后聚合结果
超时与取消模式 #
在并发程序中,我们常常需要处理超时和取消操作。Go的context包和select语句提供了优雅的方式来实现这些功能。
超时与上下文取消 #
Context的核心功能:
- 超时控制:
context.WithTimeout和context.WithDeadline - 手动取消:
context.WithCancel - 传递值:
context.WithValue - 优雅取消:通过
Done()channel通知取消事件
package main
import (
"context"
"fmt"
"sync"
"time"
)
// 一个可能耗时的操作
func slowOperation(ctx context.Context) (string, error) {
select {
case <-time.After(2 * time.Second):
return "操作完成", nil
case <-ctx.Done():
return "", ctx.Err()
}
}
// 使用超时控制
func withTimeout() {
// 创建一个带1秒超时的上下文
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel() // 确保取消函数被调用
result, err := slowOperation(ctx)
if err != nil {
fmt.Printf("超时示例出错: %v\n", err)
return
}
fmt.Printf("超时示例结果: %s\n", result)
}
// 使用手动取消
func withCancellation() {
ctx, cancel := context.WithCancel(context.Background())
// 启动一个goroutine在1秒后取消
time.AfterFunc(1*time.Second, cancel)
result, err := slowOperation(ctx)
if err != nil {
fmt.Printf("取消示例出错: %v\n", err)
return
}
fmt.Printf("取消示例结果: %s\n", result)
}
// 使用上下文控制多个goroutine
func workerWithContext(ctx context.Context, id int, wg *sync.WaitGroup) {
defer wg.Done()
fmt.Printf("工作者 %d 启动\n", id)
select {
case <-time.After(3 * time.Second):
fmt.Printf("工作者 %d 完成工作\n", id)
case <-ctx.Done():
fmt.Printf("工作者 %d 接收到取消信号: %v\n", id, ctx.Err())
}
}
func multipleWorkers() {
// 创建一个2秒后自动取消的上下文
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
var wg sync.WaitGroup
// 启动多个工作者
for i := 1; i <= 3; i++ {
wg.Add(1)
go workerWithContext(ctx, i, &wg)
}
// 等待工作者完成或超时
wg.Wait()
fmt.Println("所有工作者已退出")
}
func main() {
fmt.Println("-- 超时示例 --")
withTimeout()
fmt.Println("\n-- 取消示例 --")
withCancellation()
fmt.Println("\n-- 多工作者示例 --")
multipleWorkers()
}
超时重试模式 #
在网络请求等不稳定操作中,重试是常见需求:
重试模式的关键点:
- 指数退避:连续失败后增加重试间隔
- 最大重试次数:防止无限重试
- 超时控制:单次操作不应无限等待
- 错误处理:保留最后的错误信息供调试
package main
import (
"context"
"errors"
"fmt"
"math/rand"
"time"
)
// 模拟可能失败的操作
func doOperation(ctx context.Context) (string, error) {
// 模拟随机失败
if rand.Float32() < 0.7 {
return "", errors.New("操作失败")
}
select {
case <-time.After(500 * time.Millisecond):
return "操作成功", nil
case <-ctx.Done():
return "", ctx.Err()
}
}
// 带重试的操作
func doOperationWithRetry(maxRetries int, timeout time.Duration) (string, error) {
var lastErr error
for retry := 0; retry < maxRetries; retry++ {
ctx, cancel := context.WithTimeout(context.Background(), timeout)
result, err := doOperation(ctx)
cancel() // 及时释放资源
if err == nil {
return result, nil
}
lastErr = err
fmt.Printf("尝试 %d 失败: %v,重试中...\n", retry+1, err)
time.Sleep(time.Millisecond * 200 * time.Duration(retry+1)) // 退避策略
}
return "", fmt.Errorf("在 %d 次尝试后失败: %w", maxRetries, lastErr)
}
func main() {
rand.Seed(time.Now().UnixNano())
result, err := doOperationWithRetry(5, 800*time.Millisecond)
if err != nil {
fmt.Printf("最终错误: %v\n", err)
return
}
fmt.Printf("最终结果: %s\n", result)
}
超时与取消的实际应用 #
这些模式在以下场景尤为重要:
- HTTP客户端:防止请求无限等待
- 数据库操作:控制查询执行时间
- 分布式系统:优雅处理服务不可用
- 长时间运行的操作:提供用户取消能力
- 资源清理:确保临时资源被正确释放
并发控制模式 #
有时我们需要精确控制并发数量或并发操作。这在资源受限的环境中尤为重要。
信号量模式 #
使用带缓冲的channel实现信号量:
信号量模式的特点:
- 使用带缓冲的channel控制并发数量
- 每次操作前获取令牌,操作后释放令牌
- 可应用于任何需要限制并发的场景
- 简单高效,符合Go的设计理念
package main
import (
"fmt"
"sync"
"time"
)
// 信号量实现
type Semaphore struct {
tokens chan struct{}
}
func NewSemaphore(limit int) *Semaphore {
return &Semaphore{
tokens: make(chan struct{}, limit),
}
}
func (s *Semaphore) Acquire() {
s.tokens <- struct{}{}
}
func (s *Semaphore) Release() {
<-s.tokens
}
// 并发执行但限制最大并发数
func processWithLimit(items []int, concurrency int) {
sem := NewSemaphore(concurrency)
var wg sync.WaitGroup
for i, item := range items {
wg.Add(1)
// 获取令牌
sem.Acquire()
go func(id, val int) {
defer wg.Done()
defer sem.Release() // 释放令牌
// 模拟处理
fmt.Printf("处理项目 %d: %d 开始\n", id, val)
time.Sleep(time.Second)
fmt.Printf("处理项目 %d: %d 完成\n", id, val)
}(i, item)
}
wg.Wait()
}
func main() {
items := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
fmt.Println("限制最大3个并发:")
processWithLimit(items, 3)
}
并发与串行结合 #
有些应用需要在某些阶段并发,而在另一些阶段串行执行:
这种模式适用于:
- 数据处理前需要预处理的场景
- 并行处理后需要聚合结果的场景
- 某些阶段有依赖关系,无法并行的场景
package main
import (
"fmt"
"sync"
"time"
)
// 串行阶段
func prepare(data []int) []int {
fmt.Println("准备阶段(串行)开始")
result := make([]int, len(data))
for i, val := range data {
result[i] = val * 2
time.Sleep(100 * time.Millisecond) // 模拟处理
}
fmt.Println("准备阶段(串行)完成")
return result
}
// 并行阶段
func process(data []int) []int {
fmt.Println("处理阶段(并行)开始")
result := make([]int, len(data))
var wg sync.WaitGroup
for i, val := range data {
wg.Add(1)
go func(idx, value int) {
defer wg.Done()
// 模拟复杂处理
time.Sleep(500 * time.Millisecond)
result[idx] = value * value
fmt.Printf("处理项目 %d 完成\n", idx)
}(i, val)
}
wg.Wait()
fmt.Println("处理阶段(并行)完成")
return result
}
// 串行阶段
func finalize(data []int) int {
fmt.Println("最终阶段(串行)开始")
sum := 0
for _, val := range data {
sum += val
time.Sleep(100 * time.Millisecond) // 模拟处理
}
fmt.Println("最终阶段(串行)完成")
return sum
}
func main() {
input := []int{1, 2, 3, 4, 5}
// 串行-并行-串行处理流程
prepared := prepare(input) // 串行
processed := process(prepared) // 并行
result := finalize(processed) // 串行
fmt.Printf("最终结果: %d\n", result)
}