Go的开发工具链 #
Go语言不仅仅是一门编程语言,更是一套完整的开发生态系统。其核心是一组命令行工具,统一通过go命令调用,这套工具链遵循以下设计理念:
- 简单易用:所有工具都遵循一致的命令模式
- 开箱即用:安装Go后即可获得全部开发工具
- 标准统一:强制执行统一的代码格式和项目结构
- 自给自足:无需第三方构建工具即可完成完整开发流程
| 工具类别 | 核心命令 | 主要用途 |
|---|---|---|
| 构建相关 | go build、 go install、 go run |
编译、安装和运行Go程序 |
| 代码质量 | go fmt、 go vet、go lint |
格式化代码、检查常见错误 |
| 测试相关 | go test、 go cover |
运行测试、查看测试覆盖率 |
| 依赖管理 | go mod、 go get |
管理项目依赖和模块 |
| 文档工具 | go doc、 godoc |
查看和生成代码文档 |
编译与构建工具 #
go build #
go build是最常用的Go命令之一,用于编译Go源代码。
go build会忽略目录下以_或者.开头的go文件。
# 编译当前目录下的Go程序
go build
# 编译指定文件
go build hello.go
# 编译指定包
go build github.com/user/project
常用选项 #
# 指定输出文件名
go build -o app.exe main.go
# 跨平台编译(Windows上编译Linux可执行文件)
SET GOOS=linux
SET GOARCH=amd64
go build -o app-linux main.go
# 禁用优化和内联,用于调试
go build -gcflags="-N -l" main.go
# 使用-ldflags可以在编译时修改变量值,常用于版本号注入
go build -ldflags="-X 'main.Version=1.0.0'" main.go
# 开启所有优化
go build -gcflags="-m" main.go # 内联优化
# 开启编译器动态分析
go build -gcflags="-m=2" main.go # 更详细的内联信息
# 发布构建(禁用调试信息、启用优化)
go build -ldflags="-s -w" main.go
# -s: 去除符号表
# -w: 去除DWARF调试信息
Go支持通过构建标签(build tags)条件编译代码:
//go:build linux || darwin
// +build linux darwin
package main
// 此代码仅在Linux或MacOS上编译
使用标签构建
go build -tags=debug,mysql main.go
编译不同平台的可执行文件 #
执行go build命令前,修改环境变量可以设置编译平台
-
Windows下使用
set GOARCH=[arch]和set GOOS=[os]进行设置 -
Linux和Mac下使用
export GOARCH=[arch]和export GOOS=[os]进行设置
常见平台参数如下
| 平台 | GOARCH | GOOS |
|---|---|---|
| Windows x86_64 | amd64 | windows |
| Linux x86_64 | amd64 | linux |
| MacOS intel | amd64 | darwin |
| MacOS Apple Silicon | arm64 | darwin |
go install #
go install不仅编译程序,还会将生成的可执行文件复制到$GOPATH的bin目录下,便于全局访问。
# 安装当前目录的程序
go install
# 安装特定包
go install github.com/user/tool@latest
从Go 1.16开始,可以直接从GitHub安装命令行工具:
# 安装最新版本
go install github.com/go-delve/delve/cmd/dlv@latest
# 安装特定版本
go install github.com/golang/mock/mockgen@v1.6.0
go run #
通常使用go run快速测试代码,它会编译并立即运行程序,但不产生可执行文件:
# 运行单个文件
go run hello.go
# 运行目录下所有文件
go run .
# 运行特定包
go run github.com/user/app
# 带命令行参数运行
go run main.go -config=dev.json
go run 命令只能接受一个命令源码文件以及若干个库源码文件(必须同属于 main 包)作为文件参数,且不能接受测试源码文件。它在执行时会检查源码文件的类型。如果参数中有多个或者没有命令源码文件,那么 go run 命令就只会打印错误提示信息并退出,而不会继续执行。
编译错误undefined解决
#
在 Go 语言中,go run main.go 和 go run *.go 都是用于运行 Go 程序的命令,但它们的执行方式和适用场景有所不同:
-
go run main.go-
行为:仅编译并运行
main.go文件。 -
特点:
- 如果
main.go依赖其他文件(例如同包下的其他.go文件),这些文件不会被自动编译,除非它们被main.go直接导入(通过import语句)。 - 如果依赖的文件未被显式导入,可能会导致编译错误(如
undefined错误)。
- 如果
-
适用场景:
- 单文件程序(如简单的
main.go独立文件)。- 明确只需要运行
main.go且其他文件通过import正确引用时。
- 明确只需要运行
- 单文件程序(如简单的
-
-
go run *.go- 行为:编译并运行当前目录下所有
.go文件(匹配通配符*.go)。 - 特点:
- 会将所有
.go文件作为一个整体编译(类似于go build),因此能正确处理多文件依赖。 - 如果目录中存在多个
main包(即多个文件包含package main和func main()),会报错,因为一个程序只能有一个入口。
- 会将所有
- 适用场景:
- 多文件项目(例如同一个包
package main分布在多个文件中)。 - 需要确保所有相关文件都被编译时。
- 多文件项目(例如同一个包
- 行为:编译并运行当前目录下所有
注意:因为 Windows 的命令行解释器(如 cmd.exe 或旧版 PowerShell)对通配符(*)的处理方式与 Unix/Linux 系统不同,所以在Windows中,应该使用go run ./或者go run .。
代码质量工具 #
go fmt #
Go强制使用统一的代码格式,这是其社区一致性的关键要素。go fmt自动格式化代码,使其符合官方标准:
# 格式化当前包
go fmt
# 格式化特定文件
go fmt file.go
# 递归格式化所有子包
go fmt ./...
实际上,当你执行go fmt时,其调用的是gofmt -l -w:
# 手动使用gofmt可以提供更多选项
gofmt -s -w file.go # -s进行额外简化,-w直接写入文件
将go fmt集成到你的编辑器或IDE中,在保存时自动格式化代码。
go vet #
go vet检查代码中常见的错误和可疑的构造,可以发现编译器无法检测到的问题:
# 分析当前包
go vet
# 分析特定包
go vet github.com/user/package
# 分析所有子包
go vet ./...
go vet可以检测的问题包括:
- 无法到达的代码(unreachable code)
- 格式化字符串与参数不匹配
- 无效的结构体标签(struct tags)
- 未使用的结果(如错误)
- 可疑的赋值
- 可疑的方法签名
golint #
静态分析工具,检查代码
# 安装
go install golang.org/x/lint/golint@latest
# 使用
golint ./...
除了官方工具,还有更高级的静态分析工具staticcheck
# 安装
go install honnef.co/go/tools/cmd/staticcheck@latest
# 使用
staticcheck ./...
go fix #
当Go的API发生变化时,go fix可以自动更新代码以适应新版本:
go fix ./...
其他工具 #
go doc #
Go强调代码即文档的概念,go doc命令可以查看任何包或函数的文档:
# 查看包的文档
go doc fmt
# 查看特定函数的文档
go doc fmt.Println
# 查看完整文档(包括内部实现)
go doc -all fmt
godoc #
生成HTML文档网站:
# 安装godoc
go install golang.org/x/tools/cmd/godoc@latest
# 启动本地文档服务器
godoc -http=:6060
go generate #
go generate执行源文件中特定注释里的命令,用于自动生成代码:
// 在源文件中添加生成注释
//go:generate mockgen -source=repository.go -destination=mock_repository.go
然后运行:
go generate ./...
常见用途:
- 生成模拟对象
- 将资源文件嵌入二进制
- 生成协议缓冲区代码
- 生成静态资源绑定
go tool pprof #
Go提供了强大的性能分析工具:
# 运行CPU分析
go test -cpuprofile=cpu.prof -bench=.
# 分析CPU使用情况
go tool pprof cpu.prof
# 内存分析
go test -memprofile=mem.prof -bench=.
# 生成可视化报告
go tool pprof -http=:8080 cpu.prof
在pprof交互式控制台中,可以使用以下命令:
top:显示最消耗资源的函数list functionName:查看特定函数的代码和性能数据web:在浏览器中查看图形化调用图
go env #
环境变量管理
# 查看所有环境变量
go env
# 查看特定环境变量
go env GOPATH
# 设置环境变量
go env -w GOPROXY=https://goproxy.cn,direct
# 取消设置
go env -w GOPROXY=
Go编译过程 #
编译基础知识 #
抽象语法树 #
在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
之所以说语法是抽象的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。而类似于 if else 这样的条件判断语句,可以使用带有两个分支的节点来表示。
以算术表达式1+3*(4-1)+2为例,可以解析出的抽象语法树如下图所示:
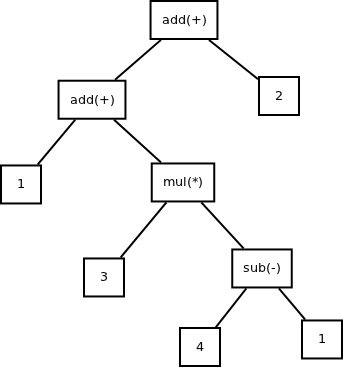
抽象语法树可以应用在很多领域,比如浏览器,智能编辑器,编译器。
静态单赋值 #
在编译器设计中,静态单赋值形式(static single assignment form,通常简写为 SSA form 或是 SSA)是中介码(IR,intermediate representation)的属性,它要求每个变量只分配一次,并且变量需要在使用之前定义。在实践中我们通常会用添加下标的方式实现每个变量只能被赋值一次的特性,这里以下面的代码举一个简单的例子:
x := 1
x := 2
y := x
从上面的描述所知,第一行赋值行为是不需要的,因为 x 在第二行被二度赋值并在第三行被使用,在 SSA 下,将会变成下列的形式:
x1 := 1
x2 := 2
y1 := x2
从使用 SSA 的中间代码我们就可以非常清晰地看出变量 y1 的值和 x1 是完全没有任何关系的,所以在机器码生成时其实就可以省略第一步,这样就能减少需要执行的指令来优化这一段代码。
在中间代码中使用 SSA 的特性能够为整个程序实现以下的优化:
- 常数传播(constant propagation)
- 值域传播(value range propagation)
- 稀疏有条件的常数传播(sparse conditional constant propagation)
- 消除无用的程式码(dead code elimination)
- 全域数值编号(global value numbering)
- 消除部分的冗余(partial redundancy elimination)
- 强度折减(strength reduction)
- 寄存器分配(register allocation)
因为 SSA 的主要作用就是代码的优化,所以是编译器后端(主要负责目标代码的优化和生成)的一部分。
指令集架构 #
指令集架构(Instruction Set Architecture,简称 ISA),又称指令集或指令集体系,是计算机体系结构中与程序设计有关的部分,包含了基本数据类型,指令集,寄存器,寻址模式,存储体系,中断,异常处理以及外部 I/O。指令集架构包含一系列的 opcode 即操作码(机器语言),以及由特定处理器执行的基本命令。
指令集架构常见种类如下:
- 复杂指令集运算(Complex Instruction Set Computing,简称 CISC);
- 精简指令集运算(Reduced Instruction Set Computing,简称 RISC);
- 显式并行指令集运算(Explicitly Parallel Instruction Computing,简称 EPIC);
- 超长指令字指令集运算(VLIW)。
不同的处理器(CPU)使用了大不相同的机器语言,所以我们的程序想要在不同的机器上运行,就需要将源代码根据架构编译成不同的机器语言。
go编译原理 #
Go语言编译器的源代码在 cmd/compile 目录中,目录下的文件共同构成了Go语言的编译器,编译器的前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作,而编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的机器码。

Go的编译器在逻辑上可以被分成四个阶段:词法与语法分析、类型检查和 AST 转换、通用 SSA 生成和最后的机器代码生成。
词法与语法分析 #
所有的编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器(lexer)。
而语法分析的输入就是词法分析器输出的 Token 序列,这些序列会按照顺序被语法分析器进行解析,语法的解析过程就是将词法分析生成的 Token 按照语言定义好的文法(Grammar)自下而上或者自上而下的进行规约,每一个 Go 的源代码文件最终会被归纳成一个 SourceFile 结构:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" }
标准的 Golang 语法解析器使用的就是 LALR(1) 的文法,语法解析的结果其实就是抽象语法树(AST),每一个 AST 都对应着一个单独的Go语言文件,这个抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等。
如果在语法解析的过程中发生了任何语法错误,都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止。
类型检查 #
当拿到一组文件的抽象语法树 AST 之后,Go语言的编译器会对语法树中定义和使用的类型进行检查,类型检查分别会按照顺序对不同类型的节点进行验证,按照以下的顺序进行处理:
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
通过对每一棵抽象节点树的遍历,我们在每一个节点上都会对当前子树的类型进行验证保证当前节点上不会出现类型错误的问题,所有的类型错误和不匹配都会在这一个阶段被发现和暴露出来。
类型检查的阶段不止会对树状结构的节点进行验证,同时也会对一些内建的函数进行展开和改写,例如 make 关键字在这个阶段会根据子树的结构被替换成 makeslice 或者 makechan 等函数。
其实类型检查不止对类型进行了验证工作,还对 AST 进行了改写以及处理Go语言内置的关键字,所以,这一过程在整个编译流程中是非常重要的,没有这个步骤很多关键字其实就没有办法工作。
中间代码生成 #
当我们将源文件转换成了抽象语法树,对整个语法树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码基本上不存在无法编译或者语法错误的问题了,Go语言的编译器就会将输入的 AST 转换成中间代码。
Go语言编译器的中间代码使用了 SSA(Static Single Assignment Form) 的特性,如果我们在中间代码生成的过程中使用这种特性,就能够比较容易的分析出代码中的无用变量和片段并对代码进行优化。
在类型检查之后,就会通过一个名为 compileFunctions 的函数开始对整个Go语言项目中的全部函数进行编译,这些函数会在一个编译队列中等待几个后端工作协程的消费,这些 Goroutine 会将所有函数对应的 AST 转换成使用 SSA 特性的中间代码。
机器码生成 #
Go语言源代码的 cmd/compile/internal 目录中包含了非常多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包进行生成 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm,也就是说Go语言能够在几乎全部常见的 CPU 指令集类型上运行。
编译器入口 #
Go语言的编译器入口是 src/cmd/compile/internal/gc 包中的 main.go 文件,这个 600 多行的 Main 函数就是Go语言编译器的主程序,这个函数会先获取命令行传入的参数并更新编译的选项和配置,随后就会开始运行 parseFiles 函数对输入的所有文件进行词法与语法分析得到文件对应的抽象语法树:
func Main(archInit func(*Arch)) {
// ...
lines := parseFiles(flag.Args())
}
接下来就会分九个阶段对抽象语法树进行更新和编译,整个过程会经历类型检查、SSA 中间代码生成以及机器码生成三个部分:
- 检查常量、类型和函数的类型;
- 处理变量的赋值;
- 对函数的主体进行类型检查;
- 决定如何捕获变量;
- 检查内联函数的类型;
- 进行逃逸分析;
- 将闭包的主体转换成引用的捕获变量;
- 编译顶层函数;
- 检查外部依赖的声明;
重新回到词法和语法分析后的具体流程,在这里编译器会对生成语法树中的节点执行类型检查,除了常量、类型和函数这些顶层声明之外,它还会对变量的赋值语句、函数主体等结构进行检查:
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCLFUNC || op == OCLOSURE {
typecheckslice(Curfn.Nbody.Slice(), ctxStmt)
}
}
checkMapKeys()
for _, n := range xtop {
if n.Op == ODCLFUNC && n.Func.Closure != nil {
capturevars(n)
}
}
escapes(xtop)
for _, n := range xtop {
if n.Op == ODCLFUNC && n.Func.Closure != nil {
transformclosure(n)
}
}
类型检查会对传入节点的子节点进行遍历,这个过程会对 make 等关键字进行展开和重写,类型检查结束之后并没有输出新的数据结构,只是改变了语法树中的一些节点,同时这个过程的结束也意味着源代码中已经不存在语法错误和类型错误,中间代码和机器码也都可以正常的生成了。
initssaconfig()
peekitabs()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
for i, n := range externdcl {
if n.Op == ONAME {
externdcl[i] = typecheck(externdcl[i], ctxExpr)
}
}
checkMapKeys()
在主程序运行的最后,会将顶层的函数编译成中间代码并根据目标的 CPU 架构生成机器码,不过这里其实也可能会再次对外部依赖进行类型检查以验证正确性。
源码文件分类 #
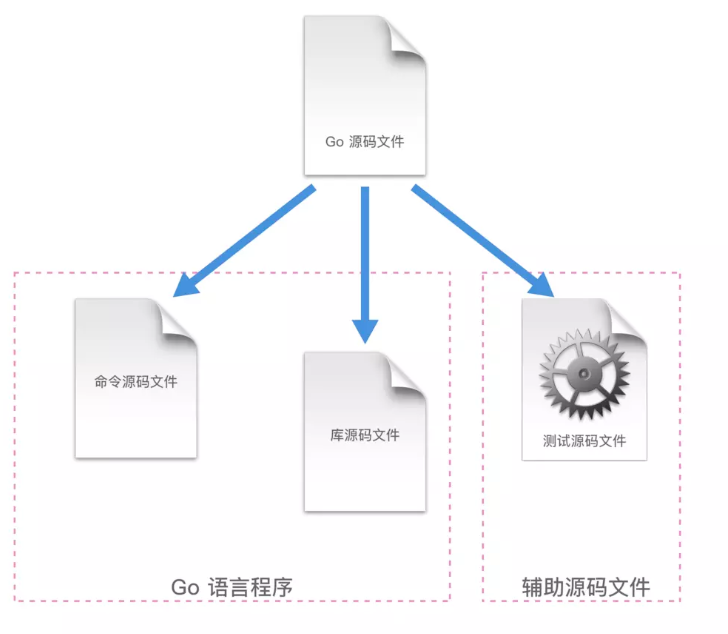
命令源码文件 #
声明自己属于 main 代码包、包含无参数声明和结果声明的 main 函数。
命令源码文件被安装以后,GOPATH 如果只有一个工作区,那么相应的可执行文件会被存放当前工作区的 bin 文件夹下;如果有多个工作区,就会安装到 GOBIN 指向的目录下。
命令源码文件是 Go 程序的入口。
同一个代码包中最好也不要放多个命令源码文件。多个命令源码文件虽然可以分开单独 go run 运行起来,但是无法通过 go build 和 go install。
库源码文件 #
库源码文件就是不具备命令源码文件上述两个特征的源码文件。存在于某个代码包中的普通的源码文件。
库源码文件被安装后,相应的归档文件(.a 文件)会被存放到当前工作区的 pkg 的平台相关目录下。
测试源码文件 #
名称以 _test.go 为后缀的代码文件,并且必须包含 Test 或者 Benchmark 名称前缀的函数。
编译指令 #
在Go语言中,编译器指令是通过特殊格式的注释实现的,通常以 //go: 开头。这些指令用于指导编译器在编译过程中执行特定操作或优化。以下是Go中常用的编译器指令及其用途:
//go:noinline
#
强制编译器不要将函数内联到调用处。
- 内联(Inlining)是编译器优化的一种,将小函数直接嵌入调用处以减少函数调用开销。
- 使用
//go:noinline可以阻止这种优化,常用于调试(如保留函数调用栈)或性能分析(防止内联干扰基准测试)。
//go:noinline
func DebugLog(msg string) {
fmt.Println("[DEBUG]", msg)
}
- 过度使用可能影响性能,仅在明确需要时使用。
//go:nosplit
#
跳过函数的栈溢出检查(Stack Split Check)。
- Go 的每个 Goroutine 初始栈较小(2KB),运行时通过栈溢出检查动态扩展栈。
//go:nosplit会禁用这一检查,常用于极低层代码(如运行时或调度器),确保函数在固定栈大小下运行。
//go:nosplit
func atomicAdd(ptr *int32, delta int32) {
// 汇编实现,无需栈操作
}
- 错误使用可能导致 栈溢出崩溃(如函数需要更多栈空间但未检查)。
- 通常与手写汇编或运行时内部函数配合使用。
//go:noescape
#
向编译器保证函数的参数不会逃逸到堆(Heap)上。
- 逃逸分析(Escape Analysis)是编译器确定变量能否在栈上分配的关键步骤。
//go:noescape声明函数参数不会逃逸到堆,帮助编译器优化内存分配(如避免堆分配)。
//go:noescape
func HashBytes(b []byte) uint64
- 仅适用于 函数签名中不包含未检查的指针(如
func(p *T)可能不适用)。 - 若声明不实(实际发生逃逸),可能导致未定义行为。
//go:norace
#
禁用当前函数的竞态检测(Race Detector)。
- Go 的竞态检测器(
-race)会在运行时检测数据竞争。 - 对性能极度敏感且确定无竞争的代码,可用此指令跳过检测。
//go:norace
func AtomicIncrement(ptr *int64) {
atomic.AddInt64(ptr, 1)
}
- 必须 100% 确定函数无数据竞争,否则可能掩盖潜在问题。
//go:linkname
#
链接到其他包中的未导出(unexported)函数或变量。
- 通过
//go:linkname可以访问其他包内部的私有符号(如runtime包中的函数)。 - 需要配合
import _ "unsafe"。
import _ "unsafe"
//go:linkname timeNow time.now
func timeNow() (sec int64, nsec int32, mono int64)
- 破坏封装性,可能导致版本升级后的兼容性问题。
- 通常用于实现高级功能(如自定义调度或性能监控)。
//go:embed
#
Go 1.16+新增,将外部文件或目录嵌入到二进制中。
- 通过
embed包和指令,将静态文件(如 HTML、配置文件)编译到程序中。 - 支持嵌入单个文件、目录或模式匹配。
import "embed"
//go:embed templates/*.html static/images/*
var content embed.FS
- 路径相对于当前 Go 文件所在目录。
- 嵌入大文件可能增加二进制体积。
//go:build
#
条件编译(替代旧的 // +build 语法)。
- 根据操作系统、架构或自定义编译标签(Tag)选择是否编译代码块。
- 使用布尔表达式组合条件(如
linux && amd64)。
//go:build darwin || (linux && amd64)
package main
- 旧语法
// +build仍可用,但//go:build更清晰且支持复杂逻辑。
//go:uintptrescapes
#
允许 uintptr 类型的参数逃逸到堆。
uintptr通常不参与逃逸分析,但在某些系统调用中需要传递指针的整数形式。- 该指令强制编译器允许
uintptr逃逸,避免被错误回收。
//go:uintptrescapes
func SyscallWrite(fd uintptr, p []byte) (n int, err error)
- 封装操作系统调用(如
syscall包)。
//go:nowritebarrierrec
#
检测并禁止函数递归触发写屏障(Write Barrier)。
- 写屏障是垃圾回收(GC)的关键机制,用于跟踪指针修改。
- 在 GC 的某些阶段(如标记阶段),禁止触发写屏障,否则可能导致死锁。
//go:nowritebarrierrec
func gcMarkWorker() {
// 标记阶段代码
}
- 主要用于 Go 运行时内部的 GC 相关代码。
//go:systemstack
#
强制函数在系统栈(System Stack)而非用户 Goroutine 栈上运行。
- Go 的 Goroutine 栈初始较小且可扩展,但某些操作(如栈扩容自身)必须在固定大小的系统栈上执行。
- 该指令确保函数运行在系统栈,避免触发栈扩展逻辑。
//go:systemstack
func runtimeCallback() {
// 处理底层任务(如调度或 GC)
}
- 运行时(Runtime)中的关键路径,如调度器或 GC。
Makefile #
Makefile 是一个强大且灵活的构建工具,具备自动化构建、处理依赖关系、任务管理和跨平台支持等优点。通过编写和使用 Makefile,开发者可以简化项目的构建过程,提高开发效率,并实现自动化的构建和发布流程。
在许多开源项目和工具中,Makefile 被广泛选择作为构建工具。它的灵活性主要体现在其具有 target(目标)的概念,相比于仅使用 Shell 脚本,Makefile 可以更好地组织和管理构建过程。
此外,Makefile 还能够与其他工具和语言进行集成,例如与 C/C++ 编译器、Go 工具链等配合使用。通过定义适当的规则和命令,可以实现与其他构建工具的无缝集成,进一步提高构建过程的灵活性和效率。
Makefile最初是用来解决C语言的编译问题的,所以和C的关系特别密切,但并不是说Makefile只能用来解决C的编译问题,也可以用来作为其他语言的编译工具,例如Java、Go等
Makefile 是由 GNU Make 工具解析执行的配置文件。要调用 Makefile,需要在命令行中使用make命令,并指定要执行的目标或规则。
Makefile可以简单的认为是一个工程文件的编译规则,描述了整个工程的自动编译和链接的规则。
语法格式 #
# 这是注释
target: prerequisites
[tab]commands
- target(目标):通常是要生成的文件的名称,可以是可执行文件或OBJ文件, 也可以是一个执行的动作名称,诸如
clean,目标的命名采用 “蛇型”(snake_case)更为常见和推荐。这是因为在 Linux 和 Unix 系统中,文件名通常使用小写字母和下划线,而不是 “驼峰命名法” 或 “中横线命名法”。 - prerequisites(依赖):是用来产生目标的材料(比如源文件),一个目标经常有几个依赖。
- commands(命令):是生成目标时执行的动作,一个规则可以含有几个命令,每个命令占一行。
**注意:**每个命令行前面必须是一个 Tab 字符。
make命令 #
在命令行中使用 make 命令调用 Makefile,并指定要执行的目标。如果未指定目标,默认会执行 Makefile 中的第一个目标。
make [target]
-f <filename>:指定要使用的 Makefile 文件名,例如 make -f mymakefile。
-C <directory>:指定 Makefile 的工作目录,例如 make -C src。
例子1
all:
@echo "Hello all"
test:
@echo "Hello test"
# 执行结果如下
$ make
Hello all
$ make all
Hello all
$ make test
Hello test
调用 make 命令时,我们得告诉它我们的目标是什么,即要它干什么。当没有指明具体的目标是什么时,那么 make 以 Makefile 文件中定义的第一个目标作为这次运行的目标。这第一个目标也称之为默认目标(和是不是all没有关系)。
命令前加了一个@, 这一符号告诉 make,在运行时不要将这一行命令显示出来。
例子 #
例子2
all: test
@echo "Hello all"
test:
@echo "Hello test"
# 执行结果如下
$ make
Hello test
Hello all
会发现当运行 make 时,test 目标也被构建了。这里需要引入 Makefile 中依赖关系的概念,all 目标后面的 test 是告诉 make,all 目标依赖 test 目标,这一依赖目标在 Makefile 中又被称之为依赖。出现这种目标依赖关系时,make工具会按从左到右的先后顺序先构建规则中所依赖的每一个目标。如果希望构建 all 目标,那么make 会在构建它之前得先构建 test 目标,这就是为什么我们称之为依赖的原因。
在实际使用中,通常一个编译过程需要生成多个目标文件(中间文件),如下
all:main.o foo.o
gcc -o simple main.o foo.o
main.o:
gcc -o main.o -c main.c
foo.o:
gcc -o foo.o -c foo.c
clean:
rm simple main.o foo.o
# 执行结果如下
$make
gcc -c main.c -o main.o
gcc -c foo.c -o foo.o
gcc -o simple main.o foo.o
$make
gcc -o simple main.o foo.o
上面的这个就是一个常见的C语言编译的过程,如果要生成可执行文件simple,那么需要main.o和foo.o,所以我们需要提前编译这两个文件。同时我们还增加了一个目标clean,用于清理编译产生的所有文件。
第二次编译并没有构建目标文件的动作,但有构建simple可执行程序的动作,我们需要了解 make 是如何决定哪些目标(这里是文件)是需要重新编译的。为什么 make会知道我们并没有改变 main.c 和 foo.c 呢?通过文件的时间戳,也就是foo.c文件的时间戳小于foo.o。当 make 在运行一个规则时,我们前面已经提到了目标和依赖之间的关系,make 在检查一个规则时,采用的方法是:如果依赖目标中相关的文件的时间戳大于依赖文件的时间戳,依赖的文件比目标更新,则知道有变化,那么需要运行规则当中的命令重新构建目标。
那为什么会执行一次gcc -o simple main.o foo.o呢?因为all文件在我们的编译过程中并不生成,即 make 在第二次编译时找不到,所以又重新编译了一遍。如果我们把all改成simple,那么就不会重新编译了。
伪目标 #
我们现在有一个目标
clean:
rm simple main.o foo.o
如果此时在工作目录中存在一个clean文件,那么我们在执行make clean的时候,make会提示'clean' is up to date.。这是因为 make 将 clean 当作文件,且在当前目录找到了这个文件,加上 clean 目标没有任何依赖,当我们要求 make 为我们构建 clean 目标时,它就会认为 clean 是最新的。
采用.PHONY关键字声明一个目标后,make 并不会将其当作一个文件来处理,而只是当作一个概念上的目标。对于假目标,我们可以想像的是由于并不与文件关联,所以每一次 make 这个假目标时,其所在的规则中的命令都会被执行。
.PHONY:clean
clean:
rm simple main.o foo.o
变量 #
系统变量 #
$*:不包括扩展名的目标文件名称;
$+:所以的依赖文件,以空格分隔;
$<:表示规则中的第一个条件;
$?:所有时间戳比目标文件晚的依赖文件,以空格分隔;
$@:目标文件的完整名称;
$^:所有不重复的依赖文件,以空格分隔;
$%:如果目标是归档成员,则该变量表示目标的归档成员名称;
定义变量 #
在 Makefile 中,变量的定义需要使用:=进行赋值操作,变量通过$()进行访问
# 定义变量
GREETING := "Hello, World!"
# 输出变量
variable:
@echo "$(GREETING)"
# 执行make,输出Hello, World!
在 Makefile 中,?= 是一个预定义的变量赋值方式,被称为 “延迟求值”(Lazy Evaluation)。
具体来说,这个符号用于设置一个变量的默认值,只有当该变量没有被显式设置时才会使用默认值。如果变量已经被设置了,那么 ?= 将不会起作用,而是保留原来的值。
# 定义变量
GREETING := "Hello!"
GREETING ?= "Hello, World!"
# 输出变量
variable:
@echo "$(GREETING)"
# 执行make,输出Hello!
数组 #
访问数组时,第一个元素可以使用$(firstword $(arr)),也可以使用$(word 1,$(arr))来访问,最后一个元素可以使用$(lastword $(arr)),也可以使用$(word index,$(arr))来访问。
# 定义数组
names := java go python
# 访问数组中元素
show:
@echo "Index1 : $(firstword $(names))"
@echo "Index2 : $(word 2,$(names))"
@echo "Index4 : $(lastword $(names))"
遍历数组
# 定义数组
names := java go python
# 访问数组中元素
show:
@for name in $(names);do\
echo "$$name";\
done