字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
所以我们判断一个字符串是否是合法的Email的方法是:
- 创建一个匹配Email的正则表达式;
- 用该正则表达式去匹配用户的输入来判断是否合法。
语法规则
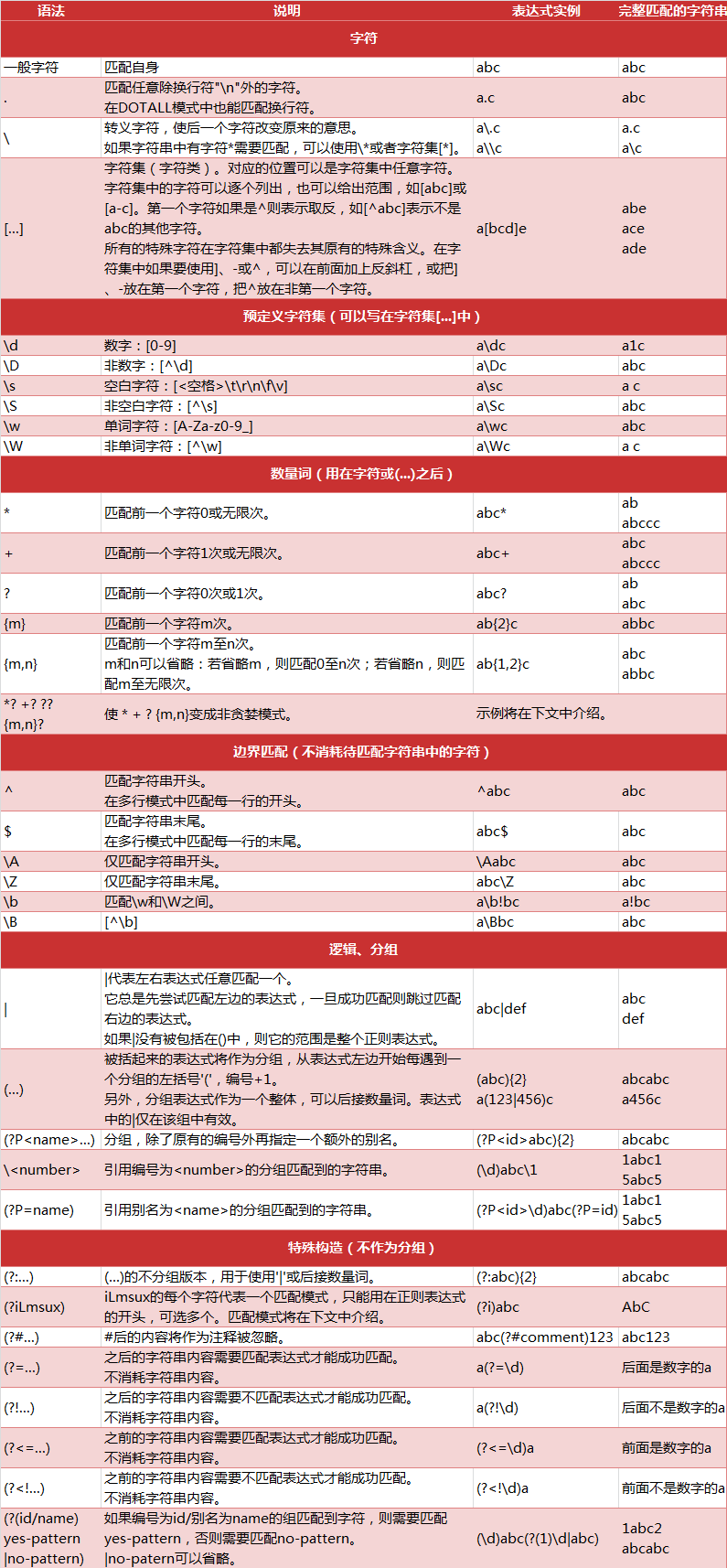
re模块
Python提供re模块,包含所有正则表达式的功能。
由于Python的字符串本身也用\转义,所以要特别注意:
s = 'ABC\\-001' # Python的字符串
# 对应的正则表达式字符串变成:
# 'ABC\-001'
因此我们强烈建议使用Python的r前缀,就不用考虑转义的问题了
s = r'ABC\-001' # Python的字符串
# 对应的正则表达式字符串不变:
# 'ABC\-001'
match()
re.match(pattern, string[, flags]):这个方法将会从 string(我们要匹配的字符串)的开头开始,尝试匹配 pattern,一直向后匹配,如果遇到无法匹配的字符,立即返回 None,如果匹配未结束已经到达 string 的末尾,也会返回 None。两个结果均表示匹配失败,否则匹配 pattern 成功,同时匹配终止,不再对 string 向后匹配。
import re
msg = '929880282@qq.com'
#匹配邮箱
r = re.compile(r'[A-Za-z0-9]+@\w+.com')
result = re.match(r,msg)
print(type(result))
print(result)
if result:
print('邮箱匹配成功')
else:
print('邮箱匹配失败')
'''
<class '_sre.SRE_Match'>
<_sre.SRE_Match object; span=(0, 16), match='929880282@qq.com'>
邮箱匹配成功
'''
search()
re.search(pattern, string[, flags]):search 方法与 match 方法极其类似,区别在于 match () 函数只检测 re 是不是在 string 的开始位置匹配,search () 会扫描整个 string 查找匹配,match()只有在 0 位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match () 就返回 None。同样,search 方法的返回对象同样 match () 返回对象的方法和属性
import re
#虽然邮箱的前三位无法匹配,但是从第四位开始符合pattern
msg = '...929880282@qq.com'
#匹配邮箱
r = re.compile(r'[A-Za-z0-9]+@\w+.com')
result = re.search(r,msg)
print(type(result))
print(result)
if result:
print('邮箱匹配成功')
else:
print('邮箱匹配失败')
'''
<class '_sre.SRE_Match'>
<_sre.SRE_Match object; span=(3, 19), match='929880282@qq.com'>
邮箱匹配成功
'''
split()
re.split(pattern, string[, maxsplit]):按照能够匹配的子串将 string 分割后返回列表。maxsplit 用于指定最大分割次数,不指定将全部分割。
import re
msg = 'abc1efg2hig3klm'
#按照数字进行分隔
result = re.split(r'\d',msg)
print(type(result))
print(result)
'''
<class 'list'>
['abc', 'efg', 'hig', 'klm']
'''
findall()
re.findall(pattern, string[, flags]):搜索 string,以列表形式返回全部能匹配的子串
import re
msg = 'anis5soid8nosnsaai9nso'
#匹配两个字母中夹一个数字
pattern = r'[a-z]\d[a-z]'
result = re.findall(pattern=pattern,string=msg)
print(type(result))
print(result)
'''
<class 'list'>
['s5s', 'd8n', 'i9n']
'''