为什么使用数据库
持久化(persistent):把数据保存在一个可掉电式的存储设备中以供以后使用,通常数据持久化就是就内存上的数据保存到磁盘上加以固化,而持久化通常使用各种关系数据库完成
数据库与数据库管理系统
数据库相关概念
- DB:数据库(Database)
- 即存储数据的“仓库”,其本质是一个文件系统。它保存了一系列有组织的数据。
- DBMS:数据库管理系统(Database Management System)
- 是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,对数据库进行统一管理和控制。用户通过数据库管理系统访问数据库中表内的数据。
- SQL:结构化查询语言(Structured Query Language)
- 专门用来与数据库通信的语言。
MySQL概述
- MySQL是一个开放源代码的关系型数据库管理系统 ,由瑞典MySQL AB(创始人Michael Widenius)公司1995年开发,迅速成为开源数据库的 No.1。
- 2008被 Sun 收购(10亿美金),2009年Sun被 Oracle 收购。 MariaDB 应运而生。(MySQL 的创造者担心 MySQL 有闭源的风险,因此创建了 MySQL 的分支项目 MariaDB)
- MySQL6.x 版本之后分为 社区版 和 商业版 。
- MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
- MySQL是开源的,所以你不需要支付额外的费用。
- MySQL是可以定制的,采用了 GPL(GNU General Public License) 协议,你可以修改源码来开发自己的MySQL系统。
- MySQL支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
- MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持 4GB ,64位系统支持最大的表文件为 8TB。
- MySQL使用 标准的SQL数据语言 形式。
- MySQL可以允许运行于多个系统上,并且支持多种语言。这些编程语言包括C、C++、Python、Java、Perl、PHP和Ruby等。
关于MySQL8.0
MySQL从5.7版本直接跳跃发布了8.0版本 ,可见这是一个令人兴奋的里程碑版本。MySQL 8版本在功能上做了显著的改进与增强,开发者对MySQL的源代码进行了重构,最突出的一点是多MySQL Optimizer优化器进行了改进。不仅在速度上得到了改善,还为用户带来了更好的性能和更棒的体验。
Oracle和MySQL选择
Oracle 更适合大型跨国企业的使用,因为他们对费用不敏感,但是对性能要求以及安全性有更高的要求。
MySQL 由于其体积小、速度快、总体拥有成本低,可处理上千万条记录的大型数据库,尤其是开放源码这一特点,使得很多互联网公司、中小型网站选择了MySQL作为网站数据库。
数据库结构
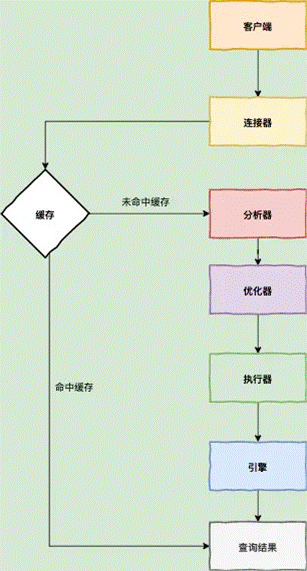
RDBMS和NO-RDBMS
关系型数据库RDBMS
这种类型的数据库是 最古老 的数据库类型,关系型数据库模型是把复杂的数据结构归结为简单的二元关系 (即二维表格形式)
关系型数据库以 行(row) 和 列(column) 的形式存储数据,以便于用户理解。这一系列的行和列被称为 表(table) ,一组表组成了一个库(database)。
表与表之间的数据记录有关系(relationship)。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。关系型数据库,就是建立在关系模型基础上的数据库。
- 优点
- 复杂查询 可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
- 事务支持 使得对于安全性能很高的数据访问要求得以实现。
SQL 就是关系型数据库的查询语言。
非关系型数据库NO-RDBMS
非关系型数据库,可看成传统关系型数据库的功能阉割版本,基于键值对存储数据,不需要经过SQL层的解析,性能非常高。同时,通过减少不常用的功能,进一步提高性能。
非关系数据库的种类
相比于 SQL,NoSQL 泛指非关系型数据库,包括了榜单上的键值型数据库、文档型数据库、搜索引擎和列存储等,除此以外还包括图形数据库。也只有用 NoSQL 一词才能将这些技术囊括进来。
键值型数据库
键值型数据库通过 Key-Value 键值的方式来存储数据,其中 Key 和 Value 可以是简单的对象,也可以是复杂的对象。Key 作为唯一的标识符,优点是查找速度快,在这方面明显优于关系型数据库,缺点是无法像关系型数据库一样使用条件过滤(比如 WHERE),如果你不知道去哪里找数据,就要遍历所有的键,这就会消耗大量的计算。
键值型数据库典型的使用场景是作为内存缓存。 Redis是最流行的键值型数据库。
文档型数据库
此类数据库可存放并获取文档,可以是XML、JSON等格式。在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录。文档数据库所存放的文档,就相当于键值数据库所存放的“值”。
MongoDB是最流行的文档型数据库。此外,还有CouchDB等。
搜索引擎数据库
虽然关系型数据库采用了索引提升检索效率,但是针对全文索引效率却较低。搜索引擎数据库是应用在搜索引擎领域的数据存储形式,由于搜索引擎会爬取大量的数据,并以特定的格式进行存储,这样在检索的时候才能保证性能最优。核心原理是“倒排索引”。
典型产品:Solr、Elasticsearch、Splunk 等。
列式数据库
列式数据库是相对于行式存储的数据库,Oracle、MySQL、SQL Server 等数据库都是采用的行式存储(Row-based),而列式数据库是将数据按照列存储到数据库中,这样做的好处是可以大量降低系统的I/O,适合于分布式文件系统,不足在于功能相对有限。
典型产品:HBase等。
图形数据库
图形数据库,利用了图这种数据结构存储了实体(对象)之间的关系。图形数据库最典型的例子就是社交网络中人与人的关系,数据模型主要是以节点和边(关系)来实现,特点在于能高效地解决复杂的关 系问题。
图形数据库顾名思义,就是一种存储图形关系的数据库。它利用了图这种数据结构存储了实体(对象)之间的关系。关系型数据用于存明确关系的数据,但对于复杂关系的数据存储却有些力不从心。如社交网络中人物之间的关系,如果用关系型数据库则非常复杂,用图形数据库将非常简单。
典型产品:Neo4J、InfoGrid等。
Sql语句
MySQL的语法规范
- 不区分大小写,但建议关键字大写,表名、列名小写
- 每条命令最好用分号结尾
- 每条命令根据需要,可以进行缩进或换行
- 注释
- 单行注释:
#注释文字 - 单行注释:
-- 注释文字 - 多行注释:
/* 注释文字 */
SQl语句分类
DDL data definition language 数据定义语句 (create alter drop)
DML data manipulation language 数据操作语句 (insert update delete)
DQL data query language 数据查询语句(select)
DCL data control lanugage 数据控制语句(grant revoke commit rollback)
MySQL常用命令
MySQL服务的登录和退出
登录:mysql 【-h 主机名 -P 端口号】 -u 用户名 -p密码
退出:exit或ctrl+C
MySQL服务的启动和停止
方式一:通过dos窗口
net start 服务名
net stop 服务名
查看服务器的版本
方式一:登录到mysql服务端
select version();
方式二:没有登录到mysql服务端
mysql --version 或 mysql --V
查看SQL执行情况
explain
mysqldump
mysqldump是mysql自带的逻辑备份工具,是mysql的客户端命令。备份原理是通过mysql协议连接到mysql服务器,将需要备份的数据查询出来,将查询出的数据转换成对应的insert等sql语句,使用时,再执行sql语句,即可将对应的数据还原。
备份
命令结构:mysqldump [options] [database] > [filename]
| 参数名 | 简写 | 含义 |
|---|---|---|
--host |
-h |
服务器主机IP地址 |
--port |
-P |
服务器mysql端口号 |
--user |
-u |
mysql用户名 |
--password |
-p |
mysql密码 |
--databases |
-B |
指定备份数据库,包括create database语句 |
--all-databases |
-A |
备份mysql服务器所有数据库,含create database语句 |
--compact |
压缩模式,产生更少的输出 | |
--comments |
-i |
添加注释信息 |
--complete-insert |
-c |
输出完成的插入语句 |
--no-data |
-d |
只备份表结构,不备份数据 |
--no-create-info |
-t |
只备份数据,不备份表结构 |
--flush-privileges |
备份mysql或相关是需要使用 | |
--quick |
-q |
不缓存查询,直接输出,加快备份速度 |
--lock-tables |
-l |
备份前,锁定所有数据库表 |
--no-create-db |
-n |
禁止生成创建数据库语句 |
--force |
-f |
当出现错误时仍然继续备份操作 |
--default-character-set |
指定默认字符集 | |
--add-locks |
备份数据库时锁定数据库表 | |
--verbose |
-v |
备份时打印各阶段信息 |
# 备份指定数据库
mysqldump -u[username] -p[password] [database] > [filename]
# 备份指定数据库的指定表,多个表使用空格分隔
mysqldump -u[username] -p[password] [database] [table1] [table2] > [filename]
# 备份指定数据库,并且忽略指定表
mysqldump -u[username] -p[password] [database] --ignore-table=[database].[table1] --ignore-table=[database].[table2] > [filename]
恢复
# 1、连接数据库
mysql -u用户名 -p密码
# 2、创建数据库
create database [database]
# 3、切换到可用数据库
use [database]
# 4、进行恢复
source [filename]
数据类型
整数类型
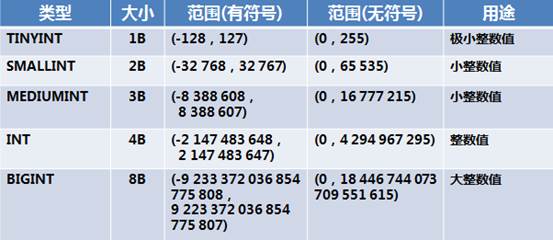
int(4):配合zerofill进行使用,显示占4位宽度,不够会补零,需要是无符号
小数类型
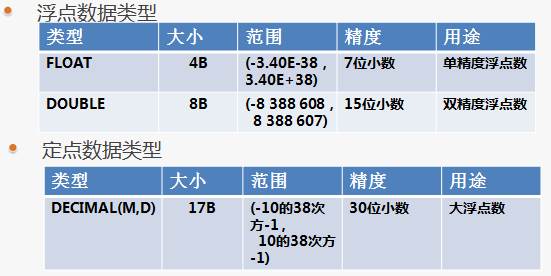
DECIMAL(max(65),max(30)):最大数字位数和最大小数位数
如果精确运算,使用DECIMAL,没有精确运算的需求,建议使用float double
字符串类型
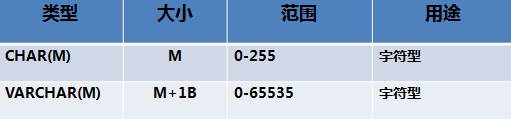
char和varchar的区别
- 场景区别:char适合存放定长字符串,varchar存放长度可变的字符串
- 后面的数字:字符个数,char后面最多可以写到255,varchar一行数据最多占65535个字节(除去Bolb类的数据类型)
- 除去其他列所占的空间,剩余的空间和varchar后面写的字符个数有关系,编码不同,一个字符所占用的存储空间也不一样,所以也会影响varchar后字符个数
- char是固定长度,char(5),如果存放了3个字符,也会按照5个字符占用存储空间
- varchar(5):可变长度,如果存储了3个字符,会按照3个字符占用存储空间。
- 速度区别:char优于varchar
- 空格的处理:char会消灭掉字符后自己插入的空格,varchar不会
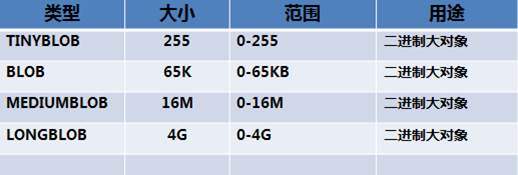
二进制数据类型
日期和时间数据类型
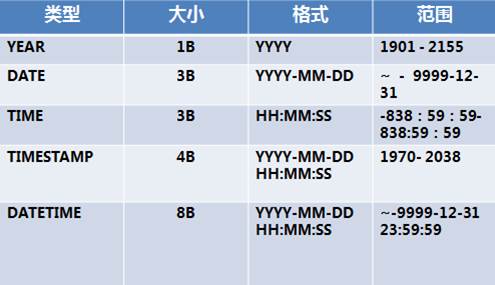
date和datetime的区别
- date类型可用于需要一个日期而不需要时间的部分
- 格式为YYYY-MM-DD 范围是'1000-01-01' 到'9999-12-31'
- datetime类型可用于需要同时包含日期和时间的信息的值
- 格式为YYYY-MM-DD HH:mm:ss 范围是'1000-01-0100:00:00' 到 '9999-12-3123:59:59'
enum和set的区别
enum只能从列出来的值中选择一个作为数据,set可以从列出来的值中选择多个值作为数据。
三大范式
第一范式
- 每列保证原子性,且唯一
第二范式
- 首先满足第一范式
- 必须要有一个主键
- 如果主键是复合主键,除了主键以外的其他列必须完全依赖于主键列,不能只依赖于主键的一部分
第三范式
- 满足第二范式
- 除了主键以外的其他列必须直接依赖于主键,不能间接依赖于主键